ChatGPT for SQL: How to Write SQL Queries with OpenAI
Introduction:
Data is only as good as the queries we run, and SQL remains the quintessential tool for accessing, modifying, and manipulating this data. But what if we could leverage artificial intelligence to help write and optimize SQL queries? Enter ChatGPT by OpenAI, an LLM (large language model) AI model with the capability to assist in writing SQL queries, among many other tasks. Through our recent exploration, we delved deep into how LLMs could revolutionize the SQL writing process.
Potential of ChatGPT for query generation
With the rise of ChatGPT by OpenAI, the age-old process of SQL writing is being reimagined. While LLMs offers a modern approach to crafting SQL queries, it's essential to understand the tool's strengths and limitations to utilize it effectively. Let's dive into some of the advantages and disadvantages of using GPT-4 for writing SQL queries.
Advantages:
- Speed: ChatGPT can generate SQL queries quickly, facilitating faster development cycles.
- Learning Tool: Beginners can leverage chatbots as a valuable learning resource, offering examples and verifying query structures.
- Broad Knowledge Base: GPT-4’s vast training data means it's aware of a wide range of SQL functions, operations, and best practices.
- Consistency: Unlike humans, the AI doesn't tire or get distracted, ensuring a consistent level of output quality.
- Adaptability: While it can handle standard SQL, you can also specify different flavors (e.g., MySQL, PostgreSQL) for more tailored query outputs.
Disadvantages:
- Lacks Deep Context: While GPT-4 can process provided information, it doesn't possess a deep understanding of a specific database's intricacies or the broader business context.
- Requires Specific Instructions: Vague or general requests can result in generalized or non-optimal outputs. Clear and specific prompts are crucial for accuracy.
- Doesn't Replace Expertise: For highly complex, nuanced, or performance-critical tasks, a seasoned database professional's experience and intuition remain invaluable.
- Security Concerns: Relying heavily on external platforms for SQL generation can pose potential security risks, especially if sensitive schema information or data is shared.
- Potential for Misinterpretation: If the user's prompt isn't clear, ChatGPT might generate a query that, while syntactically correct, might not achieve the intended outcome.
In summary, while ChatGPT presents a groundbreaking tool for SQL writing and offers numerous advantages, it's essential to approach its usage with an understanding of its limitations, especially in professional and critical applications.
Comparing ChatGPT and human analysts in SQL writing
When it comes to SQL writing, the distinction between ChatGPT and human analysts is quite fascinating. Both entities have unique strengths and capabilities that make them invaluable in their right.
ChatGPT vs. human data analysts
ChatGPT, with its expansive database of knowledge, can be likened to an entry-level data analyst with an encyclopedic grasp of syntax and basic query structures. Like an experienced SQL analyst, it can generate SQL queries swiftly and accurately for a broad range of solutions. However, unlike an analyst, ChatGPT does not possess the intuitive understanding of specific business contexts or the experiential knowledge that comes from working directly with specific datasets over time.
ChatGPT as a tool for experienced analysts
For seasoned analysts, ChatGPT can be a significant time-saver. Instead of manually crafting each query from scratch, they can use ChatGPT as a starting point, especially for repetitive or standard queries. The tool can also assist in brainstorming or in situations where the analyst is exploring unfamiliar query structures. By handling the groundwork, ChatGPT allows these experienced professionals to allocate more time to complex analyses, optimization, and strategic decision-making.
ChatGPT as a tool for new analysts
For newcomers in the realm of data analysis, ChatGPT serves as an invaluable learning resource. Junior analysts can present their SQL queries to ChatGPT to verify their correctness or seek alternative ways to structure them. When they encounter unfamiliar requirements, they can use ChatGPT to understand how such queries might be framed. Over time, by comparing their approaches with those suggested by ChatGPT, they can hone their skills, grasp best practices, and gain confidence in their SQL writing abilities.
In essence, while ChatGPT might not replace the nuanced expertise and contextual understanding of human analysts, it certainly complements their roles. Whether it's by streamlining processes for the experienced or acting as a guiding hand for the beginners, ChatGPT finds its place as an indispensable tool in the SQL landscape.
Best practices with ChatGPT for SQL writing
When to use AI for query generation
AI query generation, like that offered by ChatGPT, is a marvel for rapid development, learning, and basic to intermediate SQL tasks. However, for highly specialized or performance-critical tasks, a human touch, with its intricate understanding of the specific data and system nuances, remains irreplaceable.
How to structure a ChatGPT conversation for SQL writing
Our exploration led to a series of steps and best practices to achieve optimal SQL writing results with ChatGPT:
- Simplify the problem: Reduce your SQL problem to its simplest form. Distill the requirements and eliminate any superfluous details.
- Provide relevant context: Clearly lay out tables and columns, relationships between tables, what type of database you’re using, and sample data if possible.
- Be explicit about constraints and desired output: Specify filters you need applied, ordering, aggregations, and any performance considerations like avoiding full table scans.
- Iterate on your query: It’s unlikely the first answer will be perfect. You should expect to clarify, ask for adjustments to the query, and run the query a couple of times before landing on what you need.
Examples of SQL generation using AI
SQL is as varied as it is complex. From simple data retrievals to intricate manipulations, the spectrum of queries is vast. To understand ChatGPT's prowess in SQL writing, we tested it with some common questions SQL analysts answer. Our testing dataset is from a fictional ecommerce store.
Asking ChatGPT to write a simple SQL select
Our first task is to ask for a simple select statement, no joins, aggregations, or other functions. This one is super simple, and not likely to be useful unless someone is very new to writing SQL. Most SQL editors make it easy to preview results in a table or select all the columns in a table (here’s what it looks like in PopSQL).
The prompt we gave to Chat GPT-4 was this:
I need a SQL query for BigQuery that pulls from my ecommerce.products table and returns id, cost, name, brand, retail_price, and sku. The query should be filtered to show only "Men" department and "Swim" category.
And Chat GPT-4 responded:
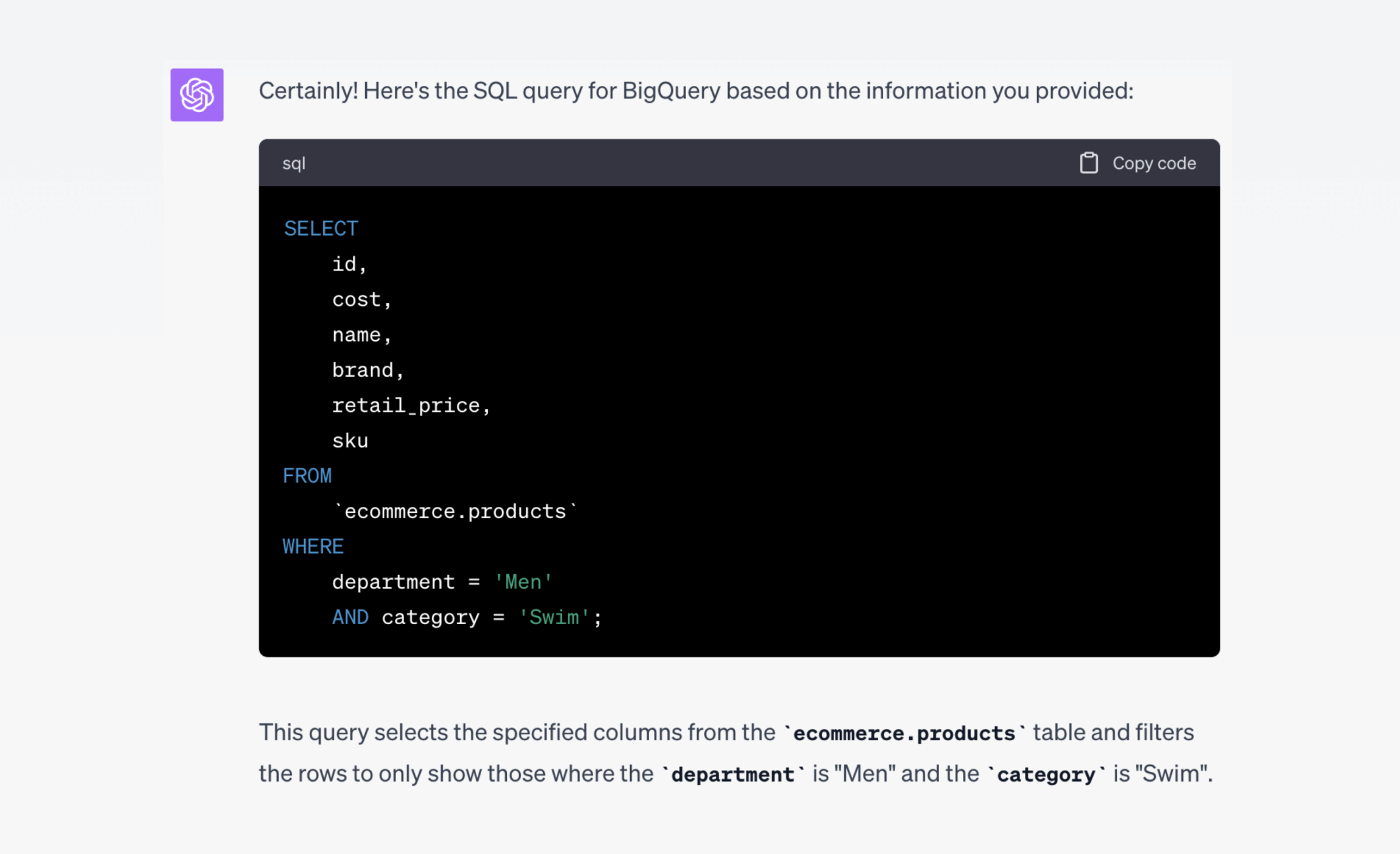
Analysis: This query is straightforward, and ChatGPT responded aptly. It even knew to surround the table reference with backticks, which is unique to BigQuery.
Asking ChatGPT to write SQL joins and SQL aggregations
Our assumption going into this section was that performance would be similar to the simple select statement. The demo database we’re working with makes foreign keys very obvious (orders.user_id joins to users.id, and other foreign keys are equally logical). For that reason, we didn’t explicitly make join keys obvious in our prompt:
I need a SQL query. My schema name is
ecommerceand the tables areusersandorders. I want an output that gives me each user’s name (users.name) and email, with the total number of orders each user has made, and the total number of items they have purchased (orders.num_of_item). Theorderstable has auser_idcolumn. I also need to filter to only show orders with status of “Complete” andcreated_atlater than Jan 1, 2020. Order the results by the total number of orders from highest at the top to lowest at the bottom.
Chat GPT responded:
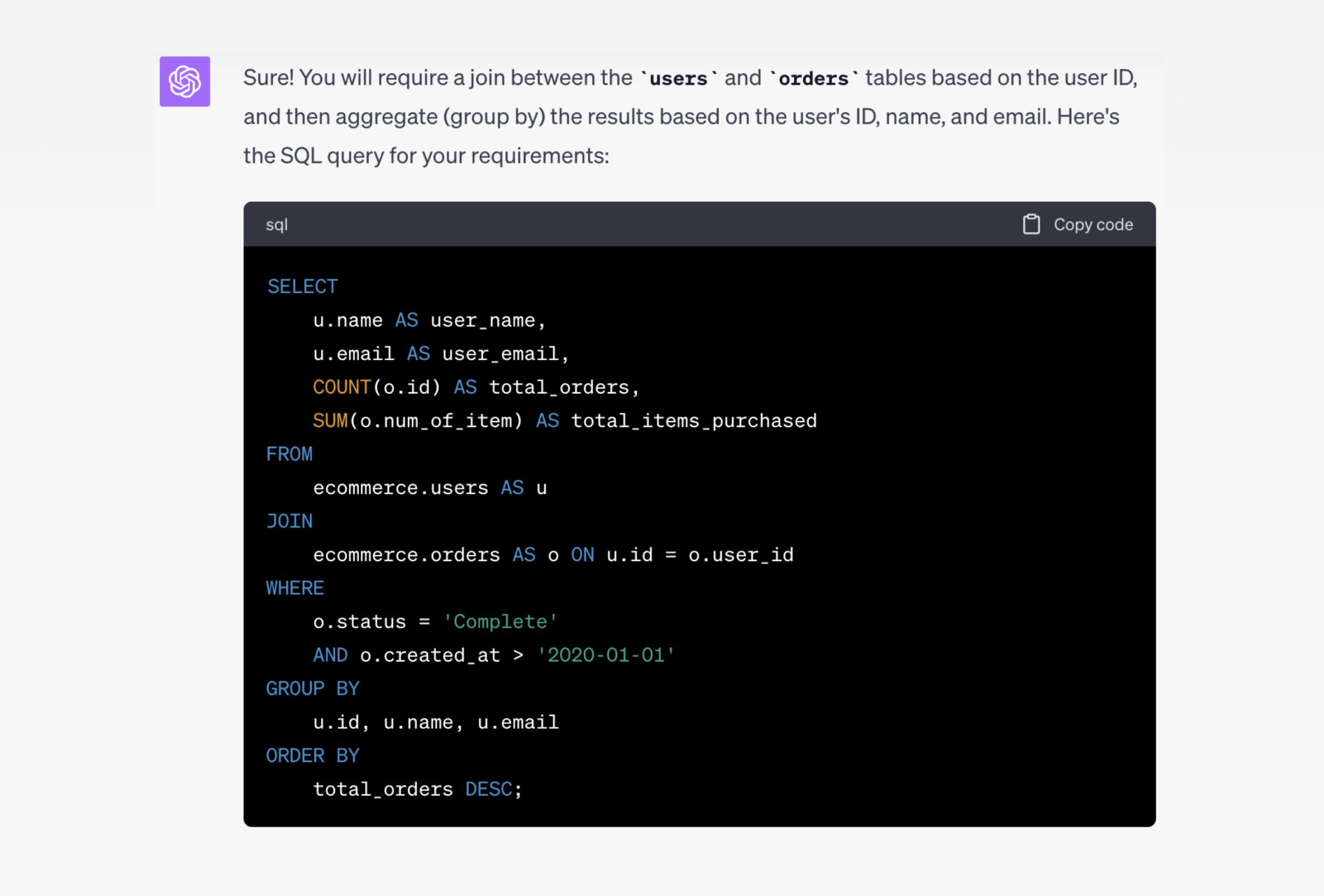
It even provided a cleaner summary of what the query does compared to the initial prompt I wrote (below the frame of the image above):
This query first joins the two tables on the user ID, then filters based on the order status and creation date. The results are grouped by the user's ID, name, and email. Finally, it orders the aggregated results based on the total number of orders in descending order.
Analysis: It performed this task perfectly, too perfectly in one spot. Our prompt contained a statement that was technically incorrect, but something a human data analyst would likely recognize and fix on behalf of the person requesting the query. We said “I also need to filter to only show orders… created_at later than Jan 1, 2020.” The where statement used > to exclude Jan 1, 2020, but the implied requirement would be to use >= to include Jan 1.
Unsurprisingly, it figured out how to join the two tables even without us explicitly mentioning the join keys. It also correctly used sum to add up the total items ordered. The only other thing worth commenting on is that it used single letter aliases for the tables, which seems unnecessary in this context, and may confuse beginners, but of course still works just fine.
Asking GPT-4 to generate SQL queries with functions
To make things a bit more interesting, we didn’t start from scratch this time. We just asked a follow up question after the previous prompt. This prompt was also purposefully more casual and less specific:
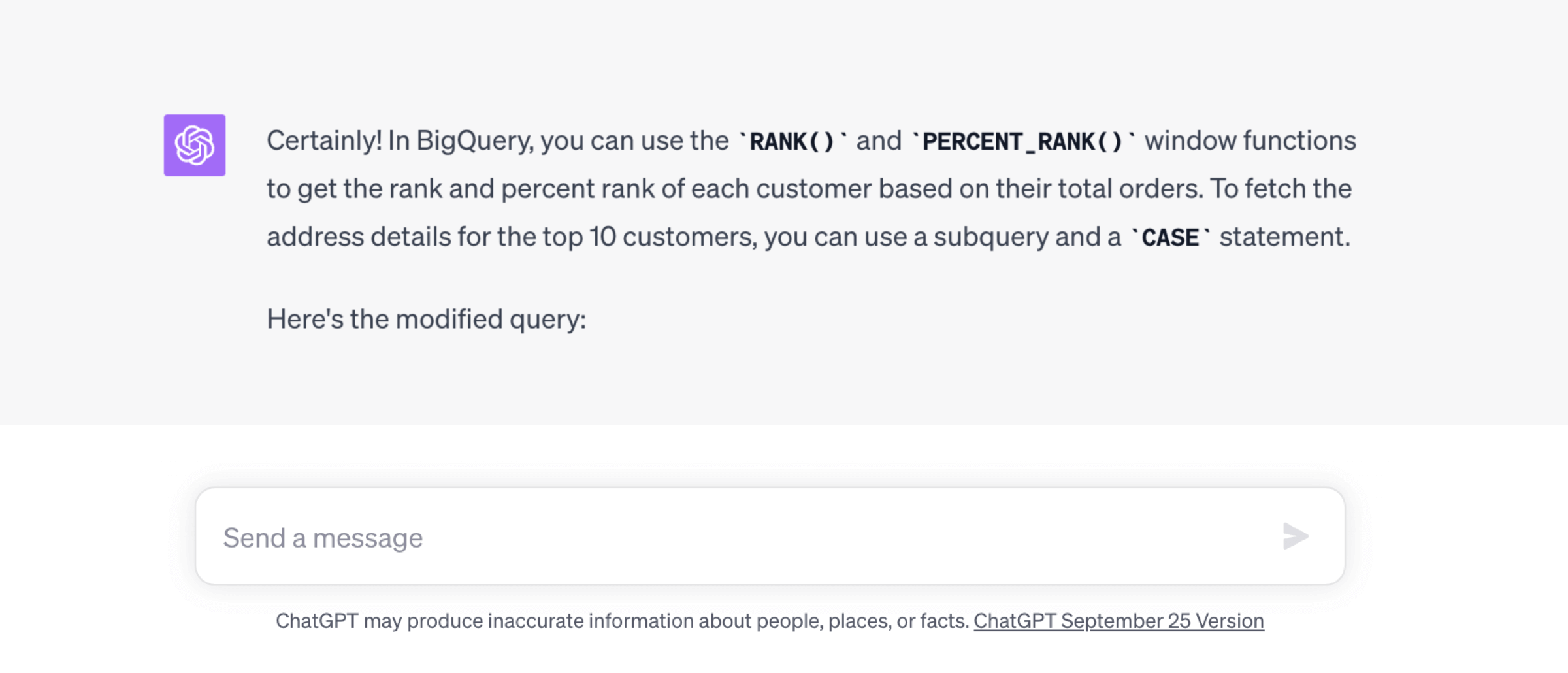
Re-write the query above, but add a column for the rank of each customer and percent rank based on total orders. This query is for BigQuery. For the top 10 customers, add their
street_address,city,state, andpostal_code(from the users table) so we can send them a prize.
ChatGPT again responded with a perfect answer that worked as expected when I ran it against the database. This response was longer than others, so we copied the raw text for most of the response rather than a screenshot:
WITH RankedUsers AS (
SELECT
u.name AS user_name,
u.email AS user_email,
COUNT(o.id) AS total_orders,
SUM(o.num_of_item) AS total_items_purchased,
RANK() OVER (ORDER BY COUNT(o.id) DESC) AS rank,
PERCENT_RANK() OVER (ORDER BY COUNT(o.id) DESC) AS percent_rank,
CASE WHEN RANK() OVER (ORDER BY COUNT(o.id) DESC) <= 10 THEN u.street_address ELSE NULL END AS street_address,
CASE WHEN RANK() OVER (ORDER BY COUNT(o.id) DESC) <= 10 THEN u.city ELSE NULL END AS city,
CASE WHEN RANK() OVER (ORDER BY COUNT(o.id) DESC) <= 10 THEN u.state ELSE NULL END AS state,
CASE WHEN RANK() OVER (ORDER BY COUNT(o.id) DESC) <= 10 THEN u.postal_code ELSE NULL END AS postal_code
FROM
ecommerce.users AS u
JOIN
ecommerce.orders AS o ON u.id = o.user_id
WHERE
o.status = 'Complete'
AND o.created_at > '2020-01-01'
GROUP BY
u.id, u.name, u.email, u.street_address, u.city, u.state, u.postal_code
)
SELECT * FROM RankedUsers
ORDER BY total_orders DESC;This query first creates a CTE (
RankedUsers) that ranks the users based on their total orders. It uses theCASEstatement to selectively show the address details only for the top 10 customers. The final result is ordered by total orders in descending order.
Before we analyze this response, we gave it a bit more of a challenge and asked it something that a real business analyst might run into:
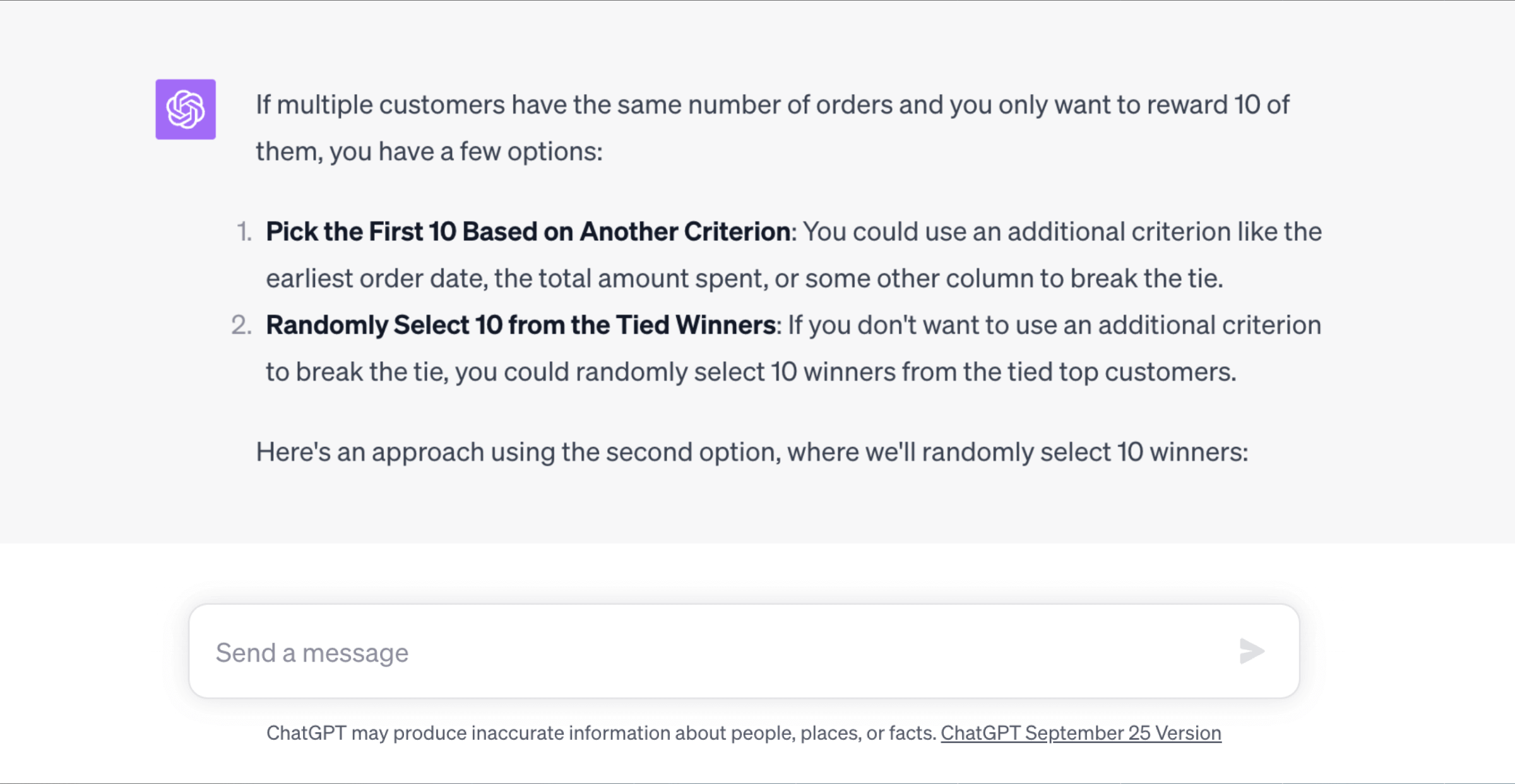
The result of that query gives me 20 winners since the top 20 customers all had the same number of orders, what do you suggest I do? I can only give 10 prizes...how can I adjust the query to get only 10 winners?
This response was also very impressive:
WITH RankedUsers AS (
SELECT
u.name AS user_name,
u.email AS user_email,
COUNT(o.id) AS total_orders,
SUM(o.num_of_item) AS total_items_purchased,
RANK() OVER (ORDER BY COUNT(o.id) DESC) AS rank,
PERCENT_RANK() OVER (ORDER BY COUNT(o.id) DESC) AS percent_rank
FROM
ecommerce.users AS u
JOIN
ecommerce.orders AS o ON u.id = o.user_id
WHERE
o.status = 'Complete'
AND o.created_at > '2020-01-01'
GROUP BY
u.id, u.name, u.email
)
, TopRankedUsers AS (
SELECT *
FROM RankedUsers
WHERE rank = 1
LIMIT 10
)
SELECT
tr.user_name,
tr.user_email,
tr.total_orders,
tr.total_items_purchased,
tr.rank,
tr.percent_rank,
u.street_address,
u.city,
u.state,
u.postal_code
FROM
TopRankedUsers tr
JOIN
ecommerce.users u ON tr.user_name = u.name AND tr.user_email = u.email
ORDER BY
tr.total_orders DESC;This query first ranks users based on their total orders. Then, it uses the TopRankedUsers CTE to limit the number of winners to 10 by selecting the first rank and limiting the rows. Finally, it joins back to the users table to retrieve the address details for these winners.
Analysis: In the follow up question we finally saw a slip up in the SQL writing decisions of ChatGPT-4. Did you notice? It used name and email to join the users table to itself rather than users.id. A small oversight, but interesting that it didn’t just add the id to the CTE.
That being said, we were very impressed with both responses in this section. It easily added rank and percent_rank with the correct arguments without being explicitly told. Its suggestions for how to limit to only 10 winners were also on point and worked just fine. The address fields were also returned correctly in both versions of the query.
Optimizing SQL queries with GPT-4
Optimizing SQL queries is important for efficient data operations, especially since most popular data warehouses charge mainly on compute cost. GPT-4 can help optimize your most costly queries, or you can ask it to optimize queries that are just taking too long to run. ChatGPT can analyze SQL statements, identify inefficiencies, and suggest optimized alternatives. For example, if presented with a suboptimal query like:
select *
from orders
where user_id in (
select user_id
from users
where status = 'active');ChatGPT might recommend employing a JOIN operation instead, leading to a more efficient execution:
select o.*
from orders o
join users u
on o.user_id = u.user_id
where u.status = 'active';This AI-driven approach not only enhances the speed and efficiency of database operations but also serves as an educational tool, offering insights into best practices and common optimization strategies. It can be helpful for new analysts who are still learning some of these best practices, and it can save time for more seasoned analysts.
A real example of optimizing a high cost query with AI
We looked at the high cost queries in our Snowflake instance at PopSQL and asked OpenAI’s chatbot to optimize some of them. To see what a response would look like with very little prompting, we asked:
Can you help me optimize this query? It costs a lot in my snowflake bill.
[pasted a big nasty SQL query here]
And the reply was extremely helpful. Of course, it will require some heavy work by an analyst to implement these suggestions, but the amount of time saved on research would be huge.
The SQL query you've presented is indeed complex and involves multiple joins and CTEs (Common Table Expressions). Here are several strategies to optimize the query in Snowflake, along with some specific suggestions:
1. Minimize the Scope of the Data:
* Only query what you need. I notice you're using
DISTINCTin several places. If you can confidently remove them, you might be able to reduce computation.2. Reduce the Complexity of Joins:
* If possible, join on indexed or primary key columns.
* You have a few casts from integer IDs to text for joining (
cast(o.id as text)). If the join can be done on integer columns, avoid casting as it adds overhead.3. Limit the Number of Derived Tables/CTEs:
* CTEs can be great for readability, but sometimes using subqueries or temporary tables can be more efficient, especially if the same CTE is used in multiple places.
4. Parallelism:
* Snowflake can parallelize some operations. If you have really large tables, consider breaking the task into smaller tasks that can be run in parallel.
5. Reduce the Use of Functions and Complex Computations in the SELECT clause:
* I see many uses of
parse\_jsonandtrimin your main SELECT. These are row-level computations and can add up if you have millions of rows. If these computations can be done once and stored, that might be beneficial.6. Query Pruning:
* Snowflake supports partitioning (they call it "micro-partitioning"). Make sure your tables are using this feature so that Snowflake can skip unnecessary chunks of data.
7. Specific Tips:
* The
events\_keyCTE contains a filter for event_name. If you have an index on event_name, this can speed up the filtering.* The main SELECT uses a left join on
analytics.events\_key. If this is the same table asdbt.events\_key, consider reusing the CTE you've already defined.* There are repetitive conditions such as
u.created\_at >= current\_date() - interval '3 months'. This can be standardized and used as a filter early in the process (as early filtering can reduce the data that needs to be processed downstream).* The condition
and cast(email as text) not like '%@gmail.%'is used twice. While it's not a high overhead condition, ensure that this type of filtering is really necessary for the logic of the query.8. Materializing Intermediate Results:
* If the results from the CTEs are reused in multiple places or queries, consider materializing the results into a temporary table. This can avoid recomputation.
9. Optimize Snowflake Configuration:
* Review your Snowflake warehouse configuration. Use a larger warehouse if needed for this computation, but be aware that costs can increase. Conversely, if your warehouse is too big for your typical workload, you might be overpaying.
10. Review Execution Plan:
* Snowflake provides a query execution plan. Review the plan to identify any steps that are particularly time-consuming or resource-intensive.
11. Regular Maintenance:
* Regularly run
OPTIMIZEon tables to keep performance at its best.Implementing these strategies will require intimate knowledge of your data, the data distribution, and the exact needs of the query. Remember to test any changes thoroughly to ensure accuracy remains intact. After optimization, it's also essential to measure performance improvements to quantify the impact of your changes.
Failed attempts to generate SQL with AI
The above example worked out really well, even when we got super vague with OpenAI’s chatbot. We also tested other workflows where it performed just as well. There were a few things that it failed at, although it was pretty hard to stump completely. Funny enough, it seemed like the biggest failures happened in areas where human analysts also tend to struggle. That makes sense since we know that LLMs are trained on content created by humans.
It struggled most when the requirements and/or context of what we needed was not clear enough from the start. For example, in the main example above, when we asked for created_at later than Jan 1, 2020, it excluded Jan 1 in the WHERE clause, which is technically correct, but in practice an experienced analyst knows the business probably wants to include Jan 1.
Another example we hit in a separate test is when we asked for weekly orders returns. It generated a perfect query, but since some weeks had no returns, the output was not suitable for creating a presentation-ready chart. In this case we asked GPT-4 what was going on:
I used the query and it worked but there are missing weeks... what happened?
It knew right away what the problem was and gave us a new query that would fix it. Something like this would likely take an inexperienced analyst quite some time to figure out and solve.

In short, it’s hard to say the chatbot ever completely failed. We tried to stump it and more often than not, it surprised us by spotting the problem with our prompts or filling in missing context. The biggest challenge is really just making sure you write useful prompts and provide the right feedback to guide it in the right direction.
When mistakes are made, that's when it is super important to have a knowledgeable SQL analyst who can recognize those mistakes and ask for an updated query. If someone who is completely new to SQL tries to generate queries with AI, they might do just fine for a while, but eventually it’ll do something unexpected and your results may be incorrect without you being able to recognize it.
PopSQL: An alternative to OpenAI’s chatbot
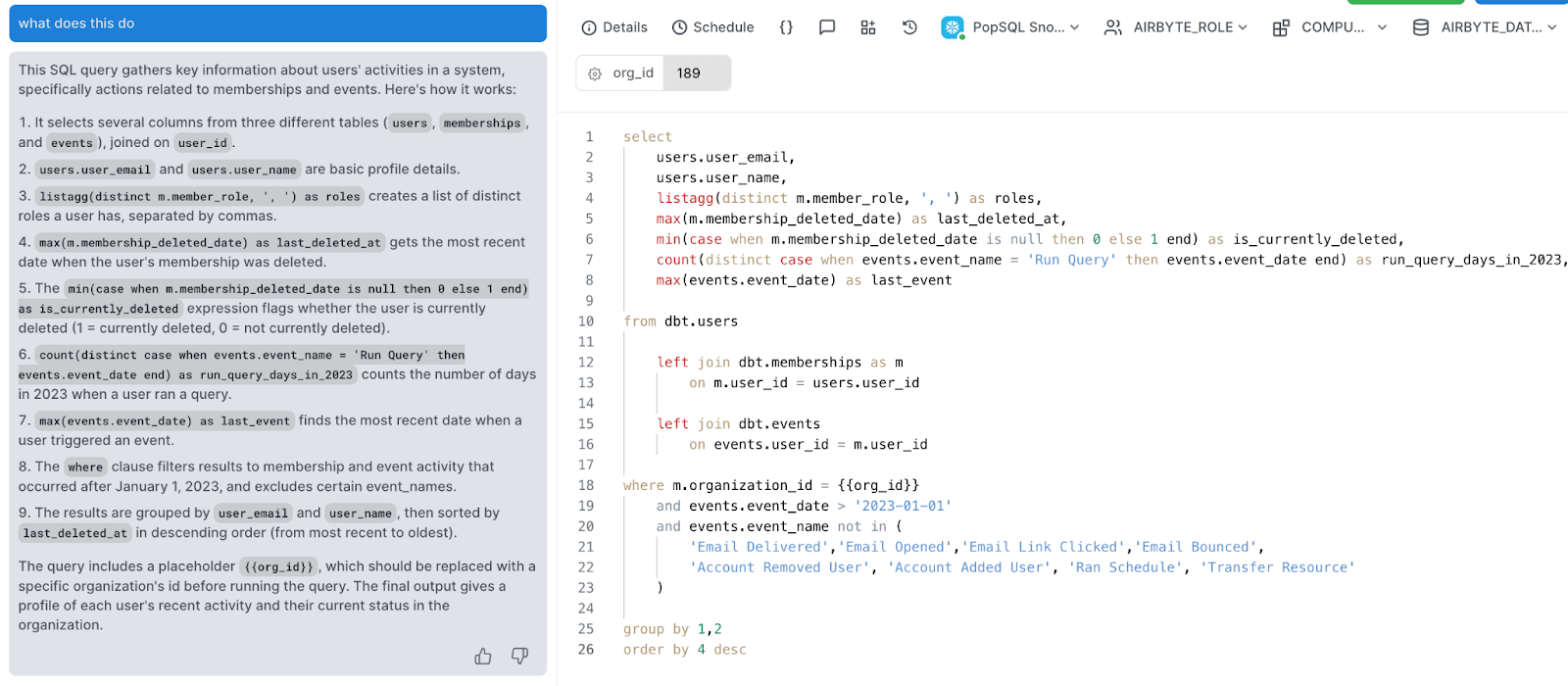
While GPT-4 offers immense capabilities, platforms like PopSQL bring integrated AI capabilities directly into your SQL workflow. PopSQL offers an embedded chatbot that uses the same LLM that powers the GPT-4 chat interface from OpenAI. The advantage of using PopSQL’s AI chat is not just to avoid switching windows, but the extra context it provides to the LLM. Your database schema and query text are included as context for your chat interaction automatically. That means you can just type “what does this query do” and PopSQL will provide all the context needed for GPT-4 to thoroughly explain. Using the same contextual information, PopSQL can auto-generate titles and descriptions for your queries for improved organization and searchability.
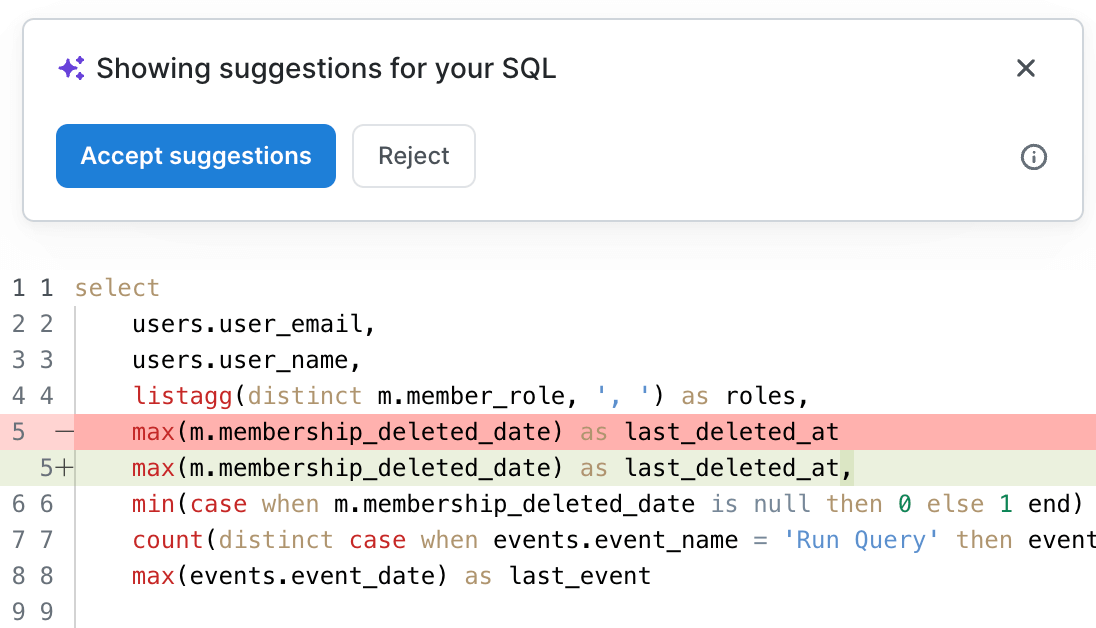
The other huge advantage of using PopSQL’s AI features is fixing errors. Every SQL analyst has had the experience of making changes to a long query and hitting an ambiguous error due to a missing comma or misspelled reference. Now you can tap into OpenAI’s hard work building one of the most advanced LLMs ever to find your missing comma. PopSQL will send the query and error to GPT-4 and interpret the answer to suggest a fix for your query.
Conclusion
In conclusion, as we enter an era where AI intertwines with various facets of technology, tools like OpenAI and PopSQL redefine our approach to SQL. They offer a blend of speed, precision, and adaptability. However, while they can be helpful, they don't replace the intricate human understanding and depth of expertise, especially in specialized tasks. Embracing these tools while recognizing their limits sets the stage for efficient and effective SQL development.
FAQs:
Can GPT-4 replace my need to learn SQL?
In some cases, yes. You can use GPT-4 just like you might sit with an analyst and tell them the output you need as they write a SQL query for you. Responses from GPT-4 still contain a lot of SQL code and references to functions, so having a basic understanding is still helpful. Knowing SQL basics is also important so you can spot logical errors and ask it to correct them. It can still be quite tedious if you know nothing about SQL since you’ll be copy-pasting query text, errors, and sample results, back and forth. Using PopSQL’s AI chat can keep your workflow in context to save some time in this.
How does ChatGPT's SQL writing compare to PopSQL's AI features?
OpenAI’s LLM is a generalized model useful for a broad range of tasks, while PopSQL's AI features are tailored specifically for SQL development. It also helps to have the context of your database schema, query text, results of recent queries, and errors, automatically shared with the chatbot.
Can GPT-4 understand and write for all database systems?
SQL syntax varies slightly between databases. While ChatGPT can adapt to many, it's essential to specify the database flavor for optimal results. In our testing we mainly focused on BigQuery and Snowflake since they are very commonly used and it performed well in both.
Are there any risks using AI for SQL generation?
If you’re altering data with your SQL queries be sure to test queries in a safe environment, to ensure they work as intended. Assuming you’re only running select statements, the only risk is returning data that is not supposed to be shared outside of your company. Be sure to confirm what’s acceptable with your data security team before sharing any query results with any outside organization or technology.
How do I optimize my interactions with chatbots for SQL writing?
Simplify your problem, provide relevant context, and be as explicit as possible with your requirements. Also remember it’s an iterative process, so share sample results, give it feedback on what needs to change, etc. as you hone the query.
Is AI the future of SQL query writing?
AI will likely play a significant role in assisting and automating many tasks in SQL writing, but the nuanced expertise of human specialists remains vital. The biggest step forward AI can offer us SQL analysts right now is the ability to save hours of wasted time trying to fix errors in queries or struggling to find the right approach to turn input data into the right output format. Asking LLMs for help with those tasks allows analysts to focus on more impactful work collaborating with business stakeholders. Even in those discussions, chatbots can be helpful in thinking up theories about why results look a certain way.
