dbt Best Practices: Superpower Your dbt Project with PopSQL

dbt is a tool that allows us to design, implement, and test workflows for the creation and population of data models. It solves common pain points in data model implementation, such as lack of standardization, complicated dependency management, and repetitive code. It integrates smoothly with popular cloud data warehouses, such as Google Cloud BigQuery, Snowflake, and AWS Redshift. Its best features include auto-generated documentation, generic and custom tests, and Jinja templating for macros and models.
dbt is a powerful tool, however, visualizing the effects of the transformations and standardizations you write is not straightforward. You need to run dbt multiple times and manually check your database and logs to examine its behavior. This process can be cumbersome and hamper the velocity of development and testing. PopSQL takes care of all this through its seamless nature–allowing you to run, share, save, and visualize queries in an intuitive UI.
PopSQL offers cool features that help you get the most out of dbt, making data analysis seamless across your teams. PopSQL has a dbt Core integration in beta, with a planned public release later this year.
dbt Setup
Before starting, you must install dbt using pip or homebrew. Once done, you should also install the necessary dbt package for your data platform such as Redshift, BigQuery, or Snowflake. Next, you must set up your profiles.yml by providing pertinent connection details.
If your data warehouse is BigQuery, here is the series of commands you will need:
1. pip install dbt-core
2. pip install dbt-bigquery
You will know that dbt is installed by running dbt and seeing the following output:
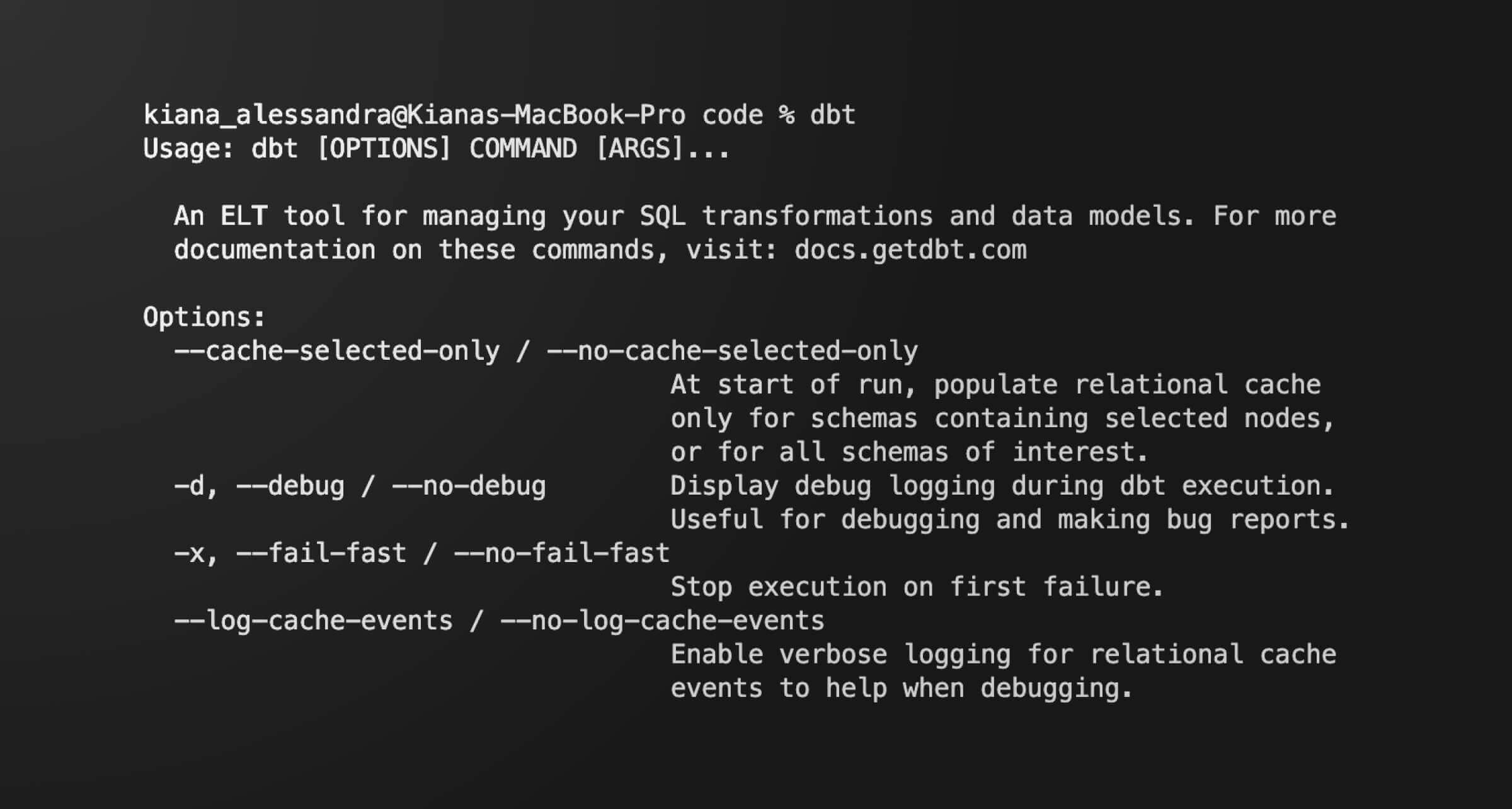
After which, you can get started on your project by running dbt init. It will generate a base template for your project. The base template can be considered the foundation of the structure we are trying to build. We can later add in more features and flesh out the structure to come up with the final product.
You will then be asked the following details:
- Project name
- Database adapter (BigQuery, Snowflake, Redshift, etc.)
- Authentication method (OAuth or Service account)
- Project ID (name of the project within the cloud platform)
- Dataset ID
- Threads (number of concurrent threads)
- Timeout in seconds (default is 300)
- Region (US, EU, etc.)
Connecting your database with PopSQL
If you do not have PopSQL yet, please download it from here to get the application running locally. In the upper right corner of the PopSQL UI, you can manage your connections by clicking the drop-down menu under the Run button.
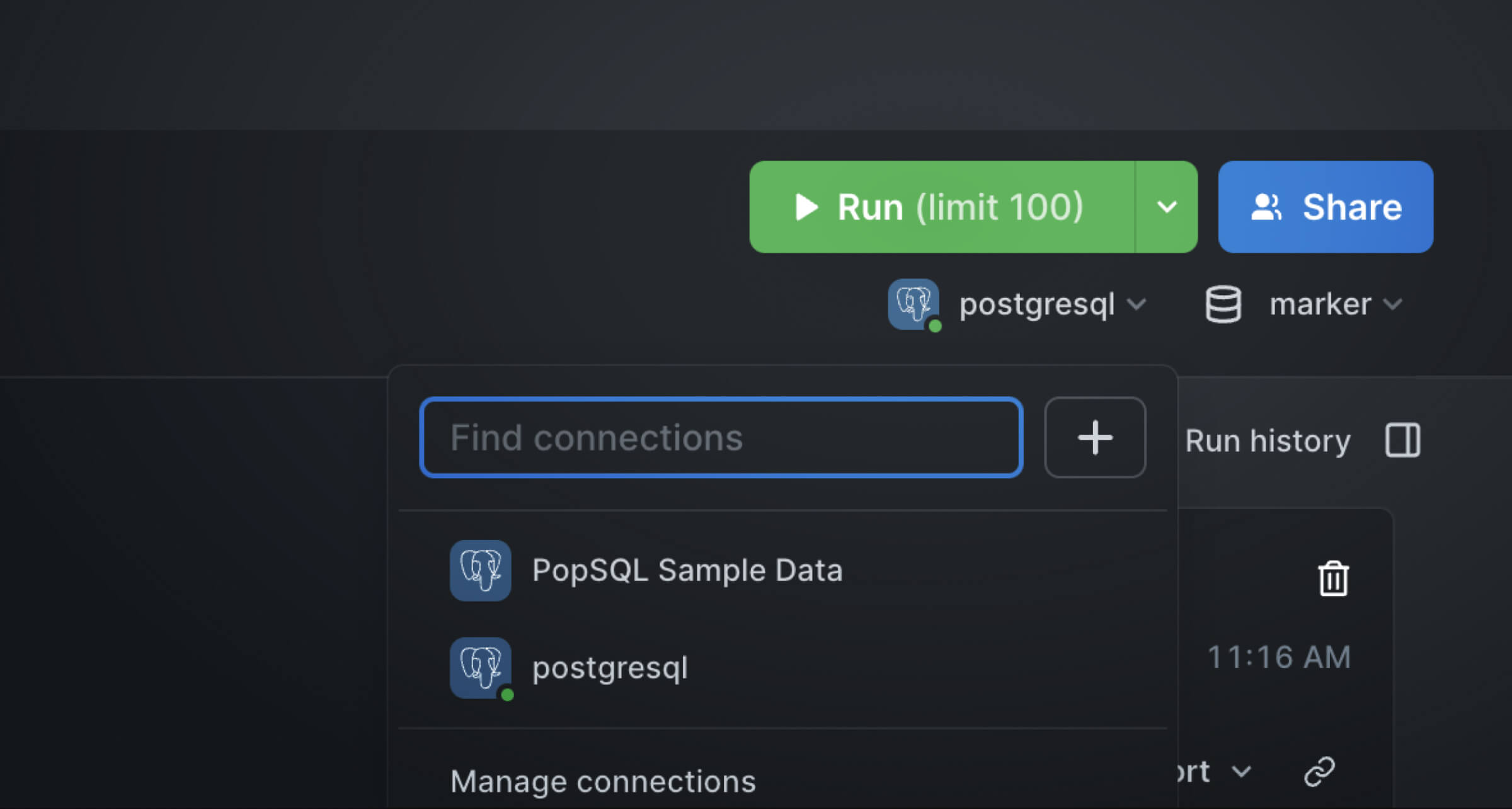
To add a new connection, click the + button and choose Add new connection:
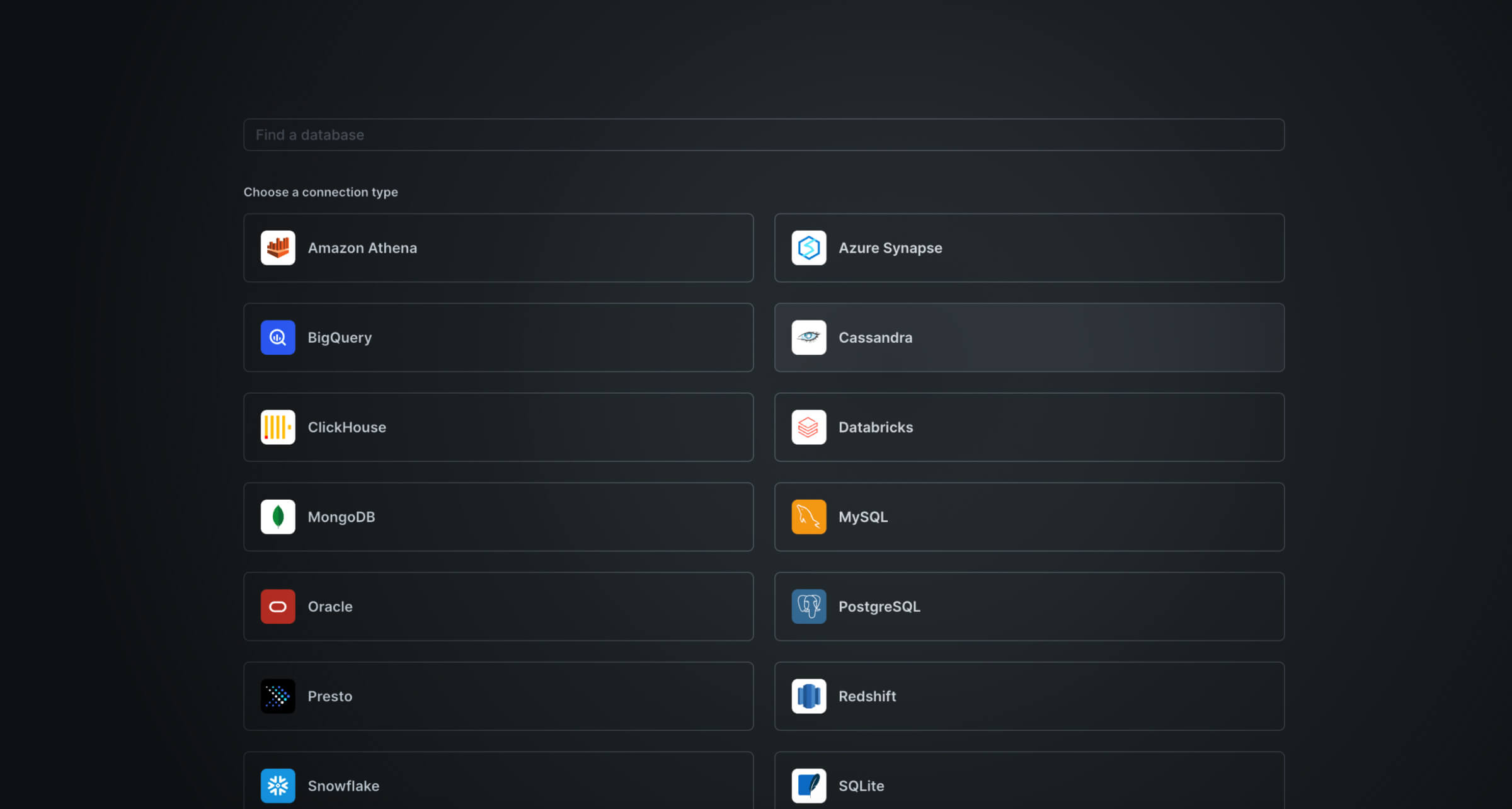 You will then be presented with a list of databases. Simply choose the database that you are using and provide the pertinent connection details. Once done, you should be able to see all your tables in the PopSQL main dashboard.
You will then be presented with a list of databases. Simply choose the database that you are using and provide the pertinent connection details. Once done, you should be able to see all your tables in the PopSQL main dashboard.
Connecting dbt and PopSQL
To connect dbt and PopSQL, first make sure that you have your dbt project files on a git repo. Note that you don't need to use GitHub; any git repo should work with PopSQL (GitLab, GitHub, or Bitbucket). Then, on PopSQL, hit Install dbt Core integration.
Next step is to add a deploy key in your Github repo, which can be found under Settings.
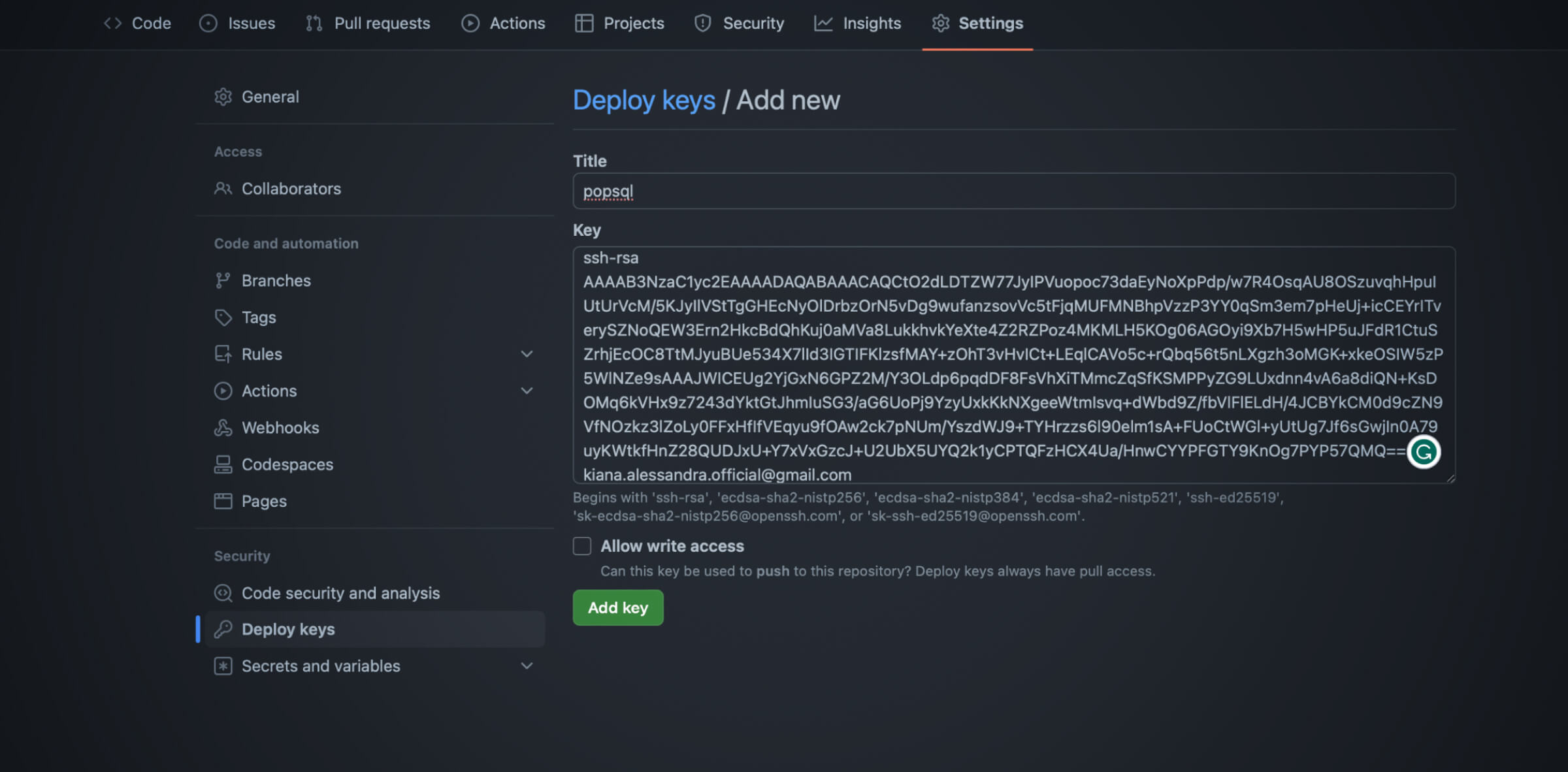
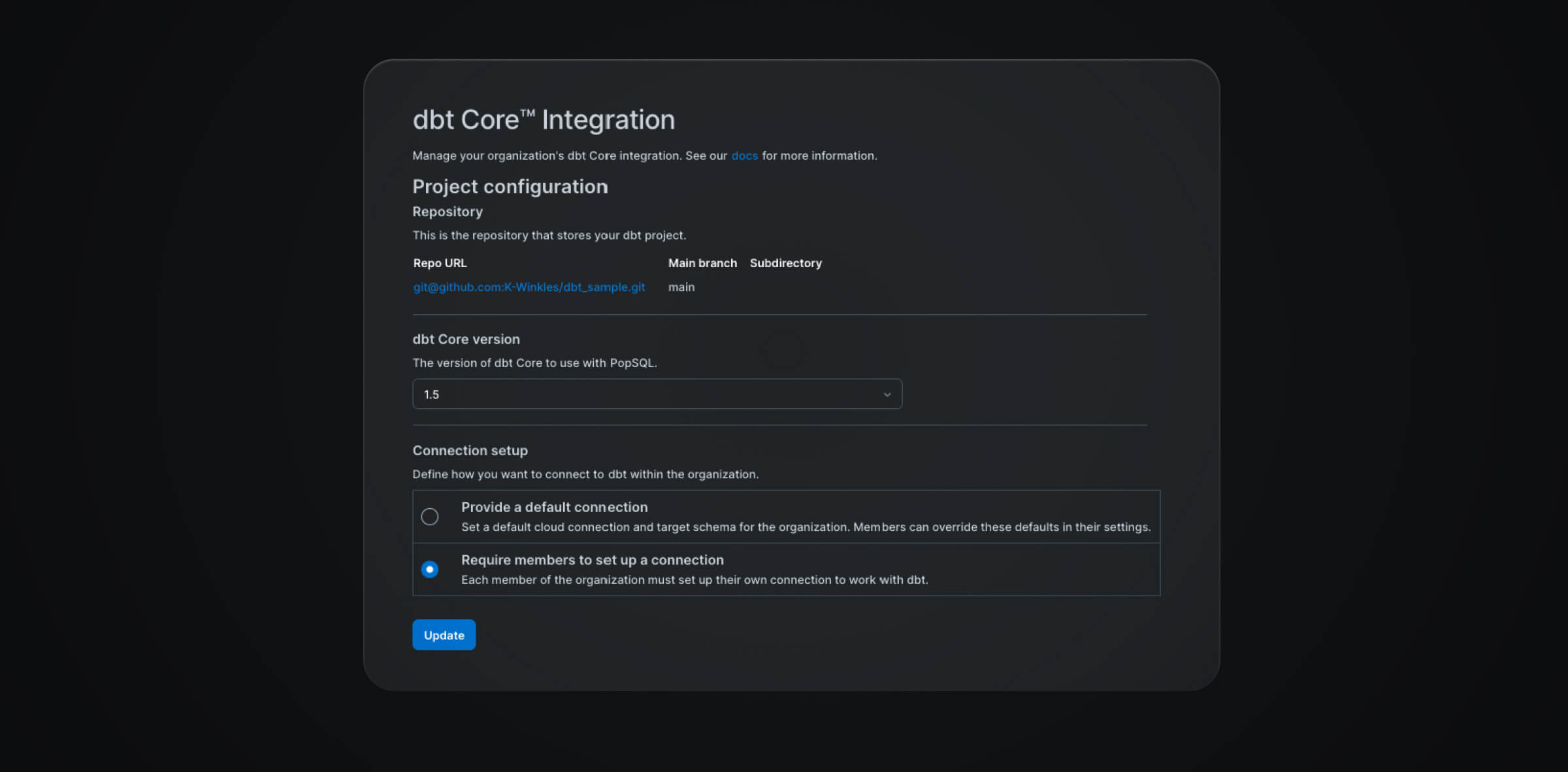
Apart from that, make sure to fill out the other details on PopSQL, such as the git repo URL, main git branch, and project subdirectory. Configure dbt by setting the dbt Core version and defining a default connection setup, if any.
Once done, you should be able to view your dbt files in PopSQL. !View your dbt files in PopSQL](https://popsql.com/static/blog/images/dbt%20Superpower_07.jpg)
Enhance dbt development with PopSQL
PopSQL is the first SQL editor with built-in dbt Core™ support. This integration makes your life simple by allowing you to focus on dbt development without the fuss of several dbt runs. In the following sections, you will see how you can truly superpower your dbt development with PopSQL.
Reduced context switching
Context switching is real pain in dbt development. In practice, developers are constantly switching between their IDE, terminal, and browser. As mentioned above, it can be a jarring experience, especially for novices.
Consider a scenario wherein you are developing a full application that uses not just dbt, but also version control like Gitlab, a data warehouse solution like Snowflake/AWS Redshift/GCP BigQuery, and various processing steps written in either bash or Python and executed via an orchestration tool. The development process becomes overwhelming especially for newly onboarded resources. Using PopSQL to reduce context switching should augment productivity.
Simplified data exploration and visualization
Prior to writing models, tests, and macros, the first step is to understand your data. To do this, you have to dig through your data and understand how each part relates to another. This is also one of the initial steps to creating a data model, which is a blueprint for the database. PopSQL simplifies data exploration using queries.
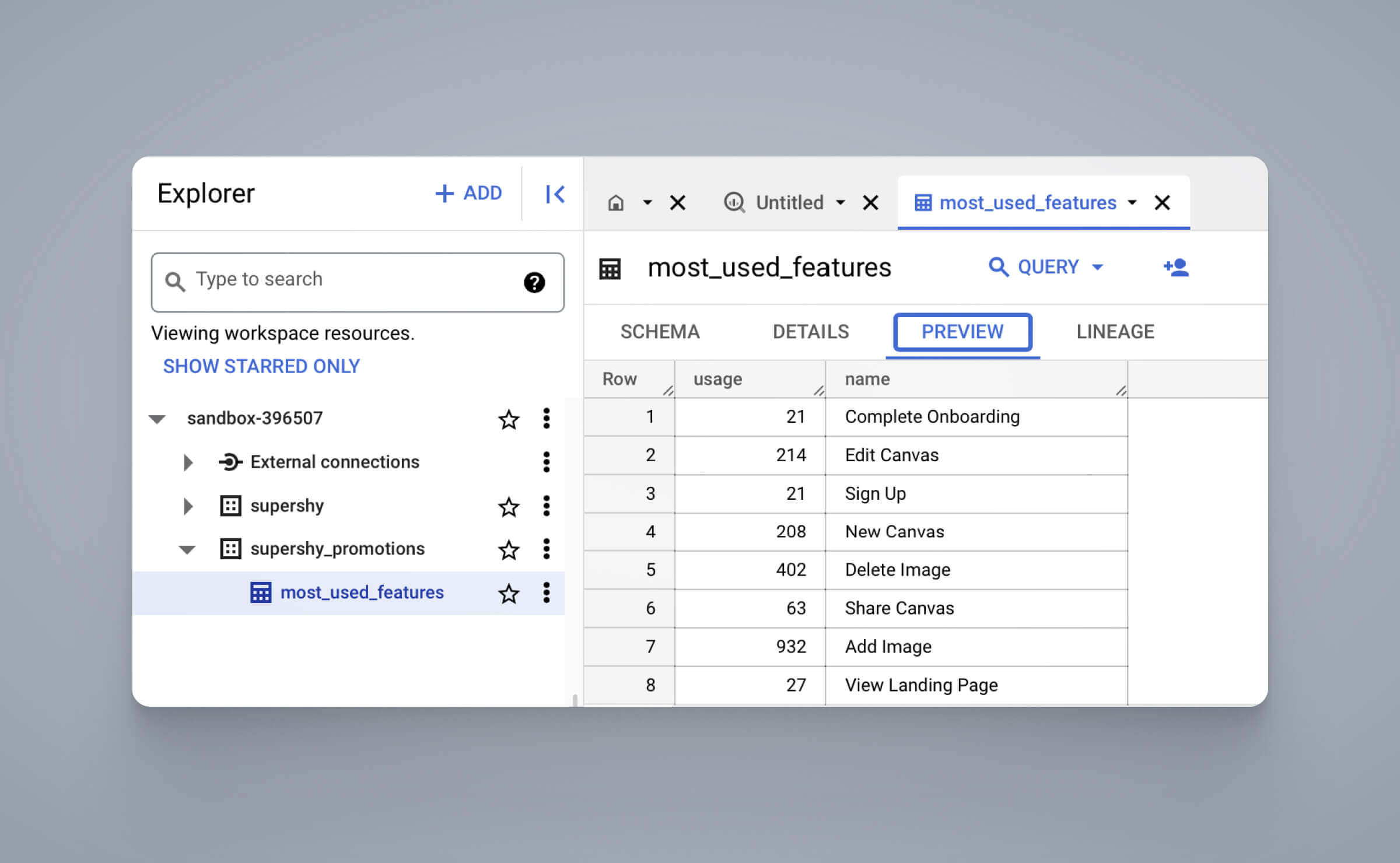
Let’s take a look at the different features in the data on PopSQL by looking at a sample table named events. In this scenario, events refer to user actions on a website such as Start Subscription, Delete Image, and others.
SELECT DISTINCT name FROM eventsYou will see the output as follows:
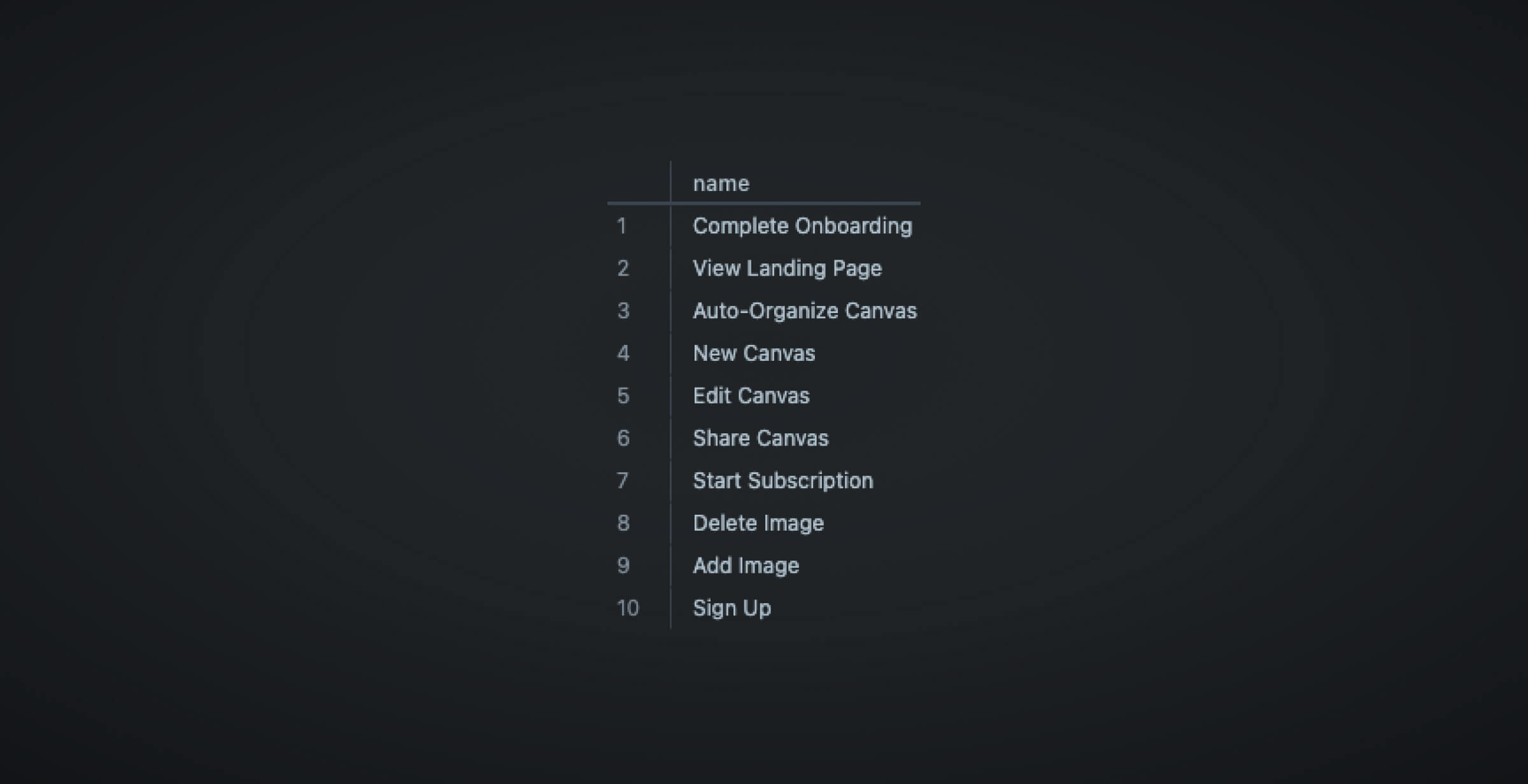
From here, we can see that we have 10 unique features that we can possibly analyze. Let’s try to answer a simple question: “Which feature is used the most?”
SELECT
name,
COUNT(
*
) AS invocations
FROM events
GROUP BY name
ORDER BY invocations DESC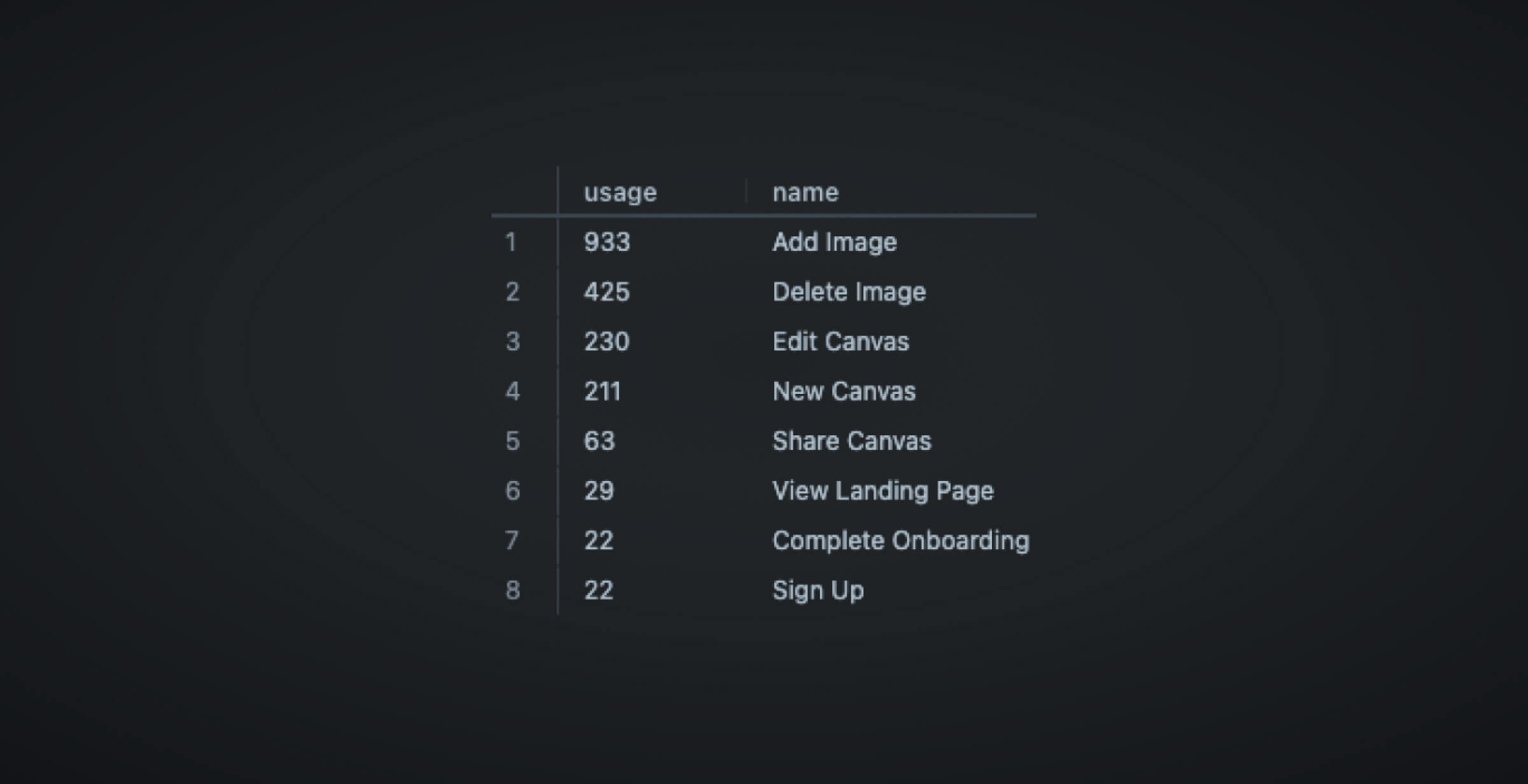
Okay, now we have a general feeling of what features are most used. We can create a simple visualization to make our findings more intuitive. All we need to do is highlight the query in question and hit Add to dashboard.
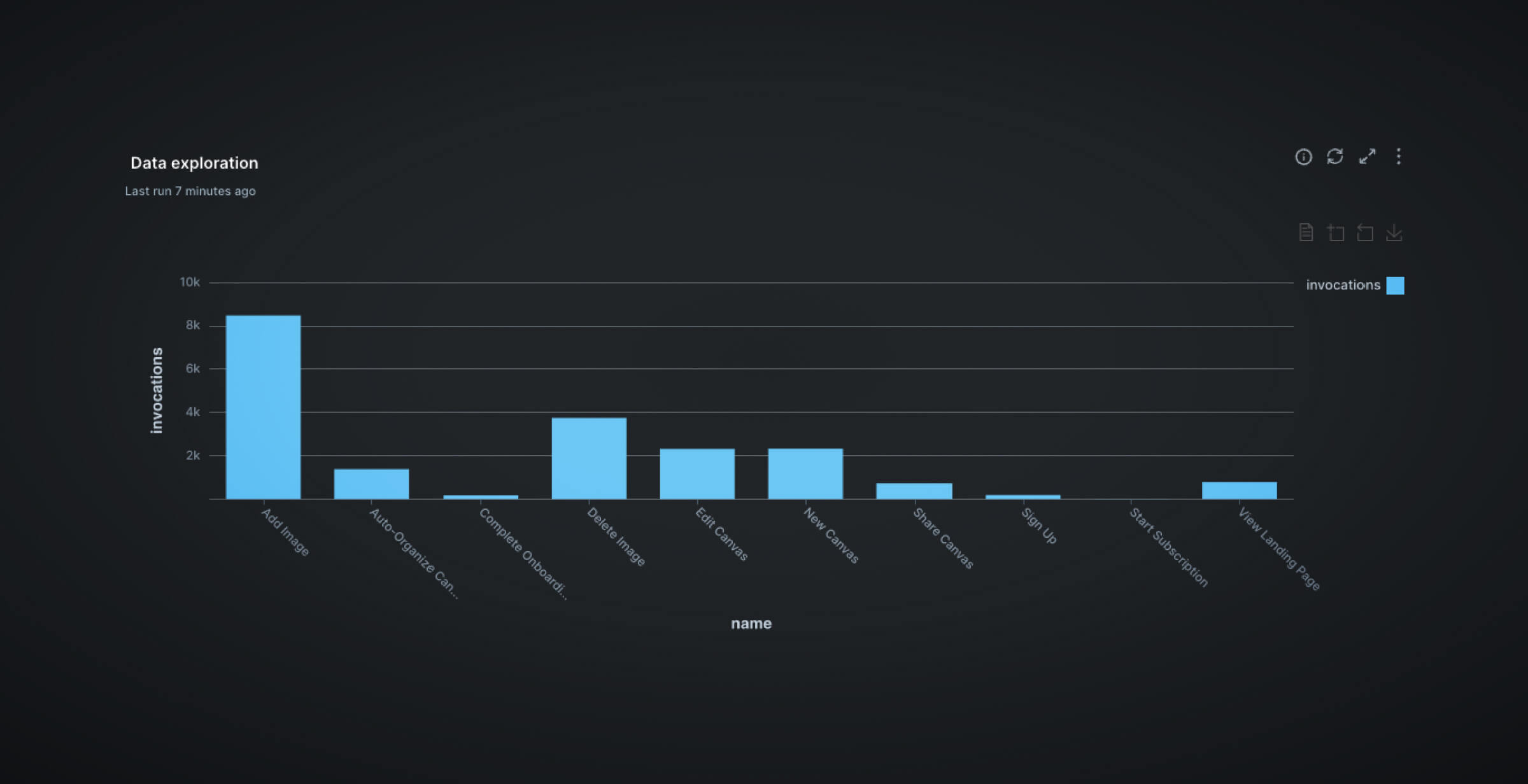
Regardless of the task at hand, developers should always start by understanding their data, and running simple queries such as the ones above are very useful for that purpose.
Preview your dbt model results instantly
Testing model queries can be cumbersome when you need to execute dbt run every time because if your assets are not properly tagged, you run the risk of redundantly running everything again. Executing a full dbt run could take up to 30 minutes for large data with many tables because there is latency between the local machine and the cloud. Hence, using PopSQL to test your queries quickly will shave off a large chunk of development time.
Now, let us define a model that tells us which features were most used during a certain time period. Let’s assume that this is relevant to our stakeholders because we ran a 5-day promotion where the full version of the application was available to everybody. We want to know what features were most interesting to our customers.
{{ config(
materialized="table",
schema="promotions"
) }}
WITH base_table AS (
SELECT
*
FROM users u
INNER JOIN events e
ON u.id = e.user_id
), most_used_features AS (
SELECT
COUNT(*) AS usage,
name
FROM base_table
WHERE time >= '2020-03-24'
AND time <= '2020-03-29'
GROUP BY name
ORDER BY usage DESC
) SELECT * FROM most_used_featuresBefore we execute the dbt build command, we can use the Preview button compile and run the query. That way you can check for problems without waiting for a full dbt run.
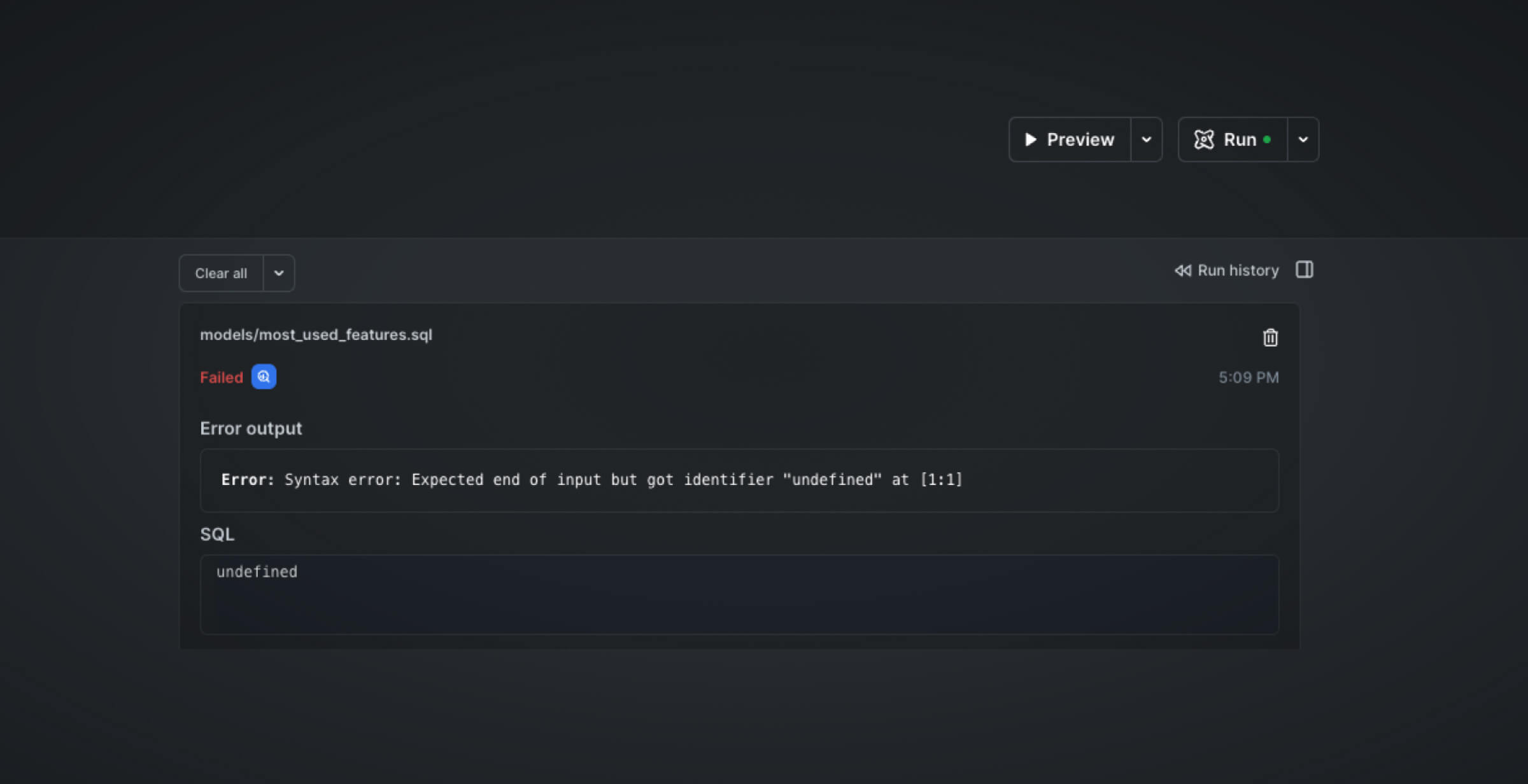
In the screenshot above, the run failed because the model file had a syntax error. This is one example of how you do not need to switch contexts. To fix the error, simply fix the syntax error within PopSQL. Then, once verified working, we can go on and hit Run to materialize the tables in our cloud data warehouse.
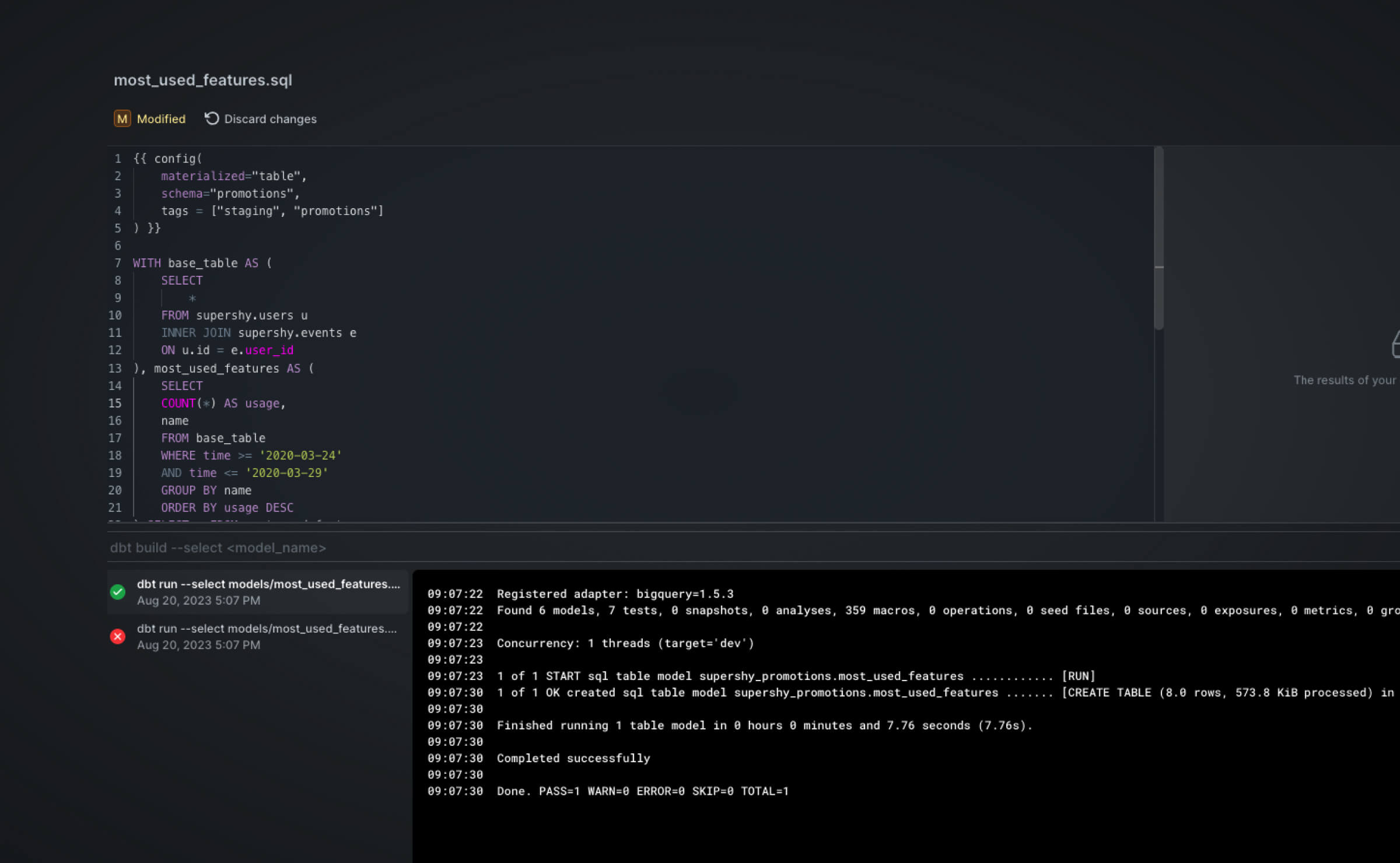
Unlike traditional dbt development, where users have to comb through logs to identify the errors, you can see that any problems are logged conveniently within PopSQL as shown in the screenshot above. Once the run is completed, we can view the results in our platform of choice. In this instance, it’s BigQuery as shown below:
Speed up macros development
Using Jinja to write macros can sometimes get tricky especially when it comes to testing. This is because in order to test the macro, you will have to execute dbt run to see its effects. It can get very cumbersome.
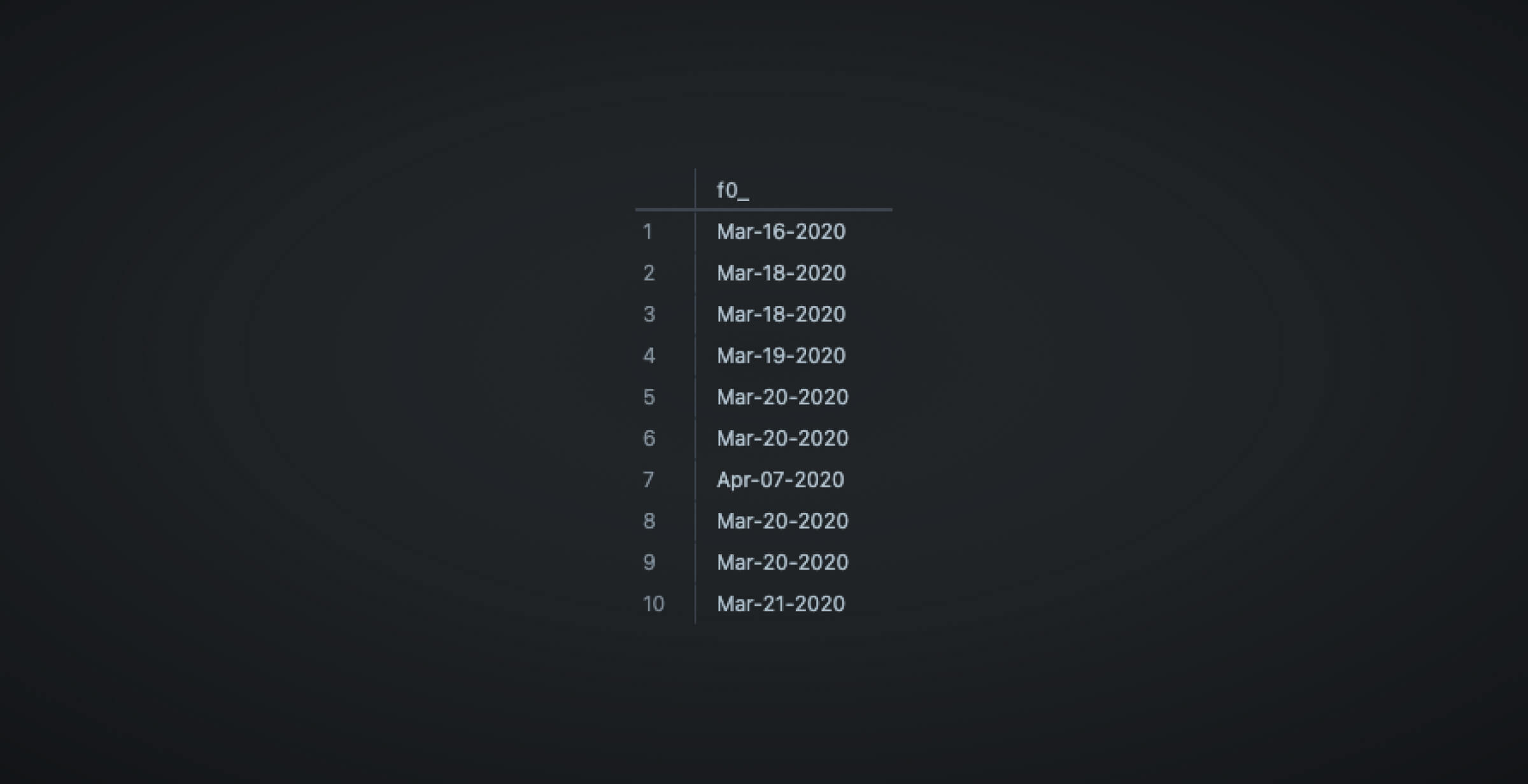
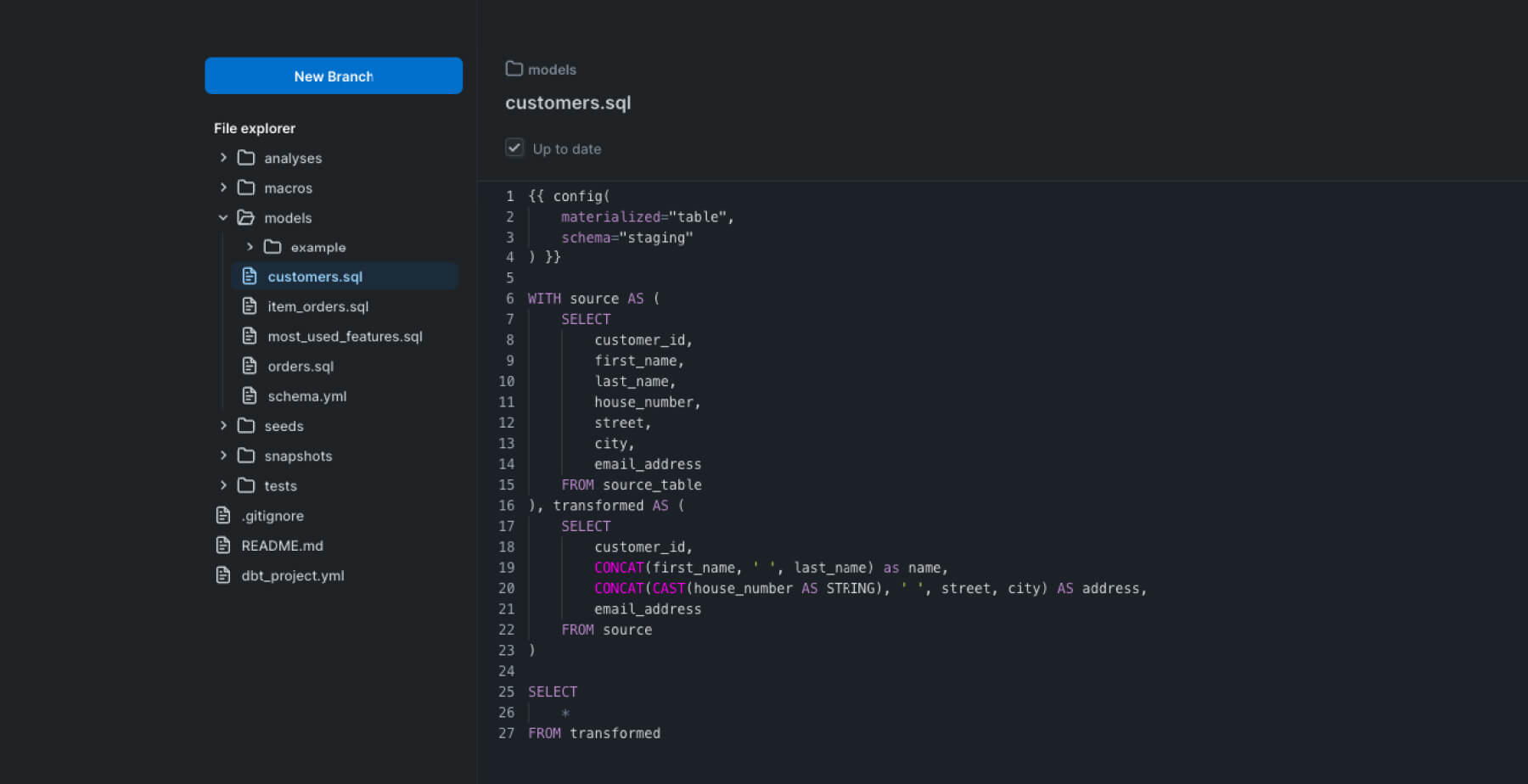
Let’s say that we’ve written a macro that converts timestamps to dates by converting the date fields to Pacific time and removing the time component. The format is as follows: MM-DD-YYYY. The macro would look like this:
{% macro timestamp_to_date(time_col) %}
FORMAT_TIMESTAMP("%b-%d-%Y", {{ time_col }})
{% endmacro %}We can test this out first on PopSQL like so:
SELECT FORMAT_TIMESTAMP("%b-%d-%Y", time) FROM supershy.eventsWhich will output this:
Then once we are confident, we can also apply the macros to other queries. We can transform the query from the previous step and aggregate data on a daily basis as shown:
{{ config(
materialized="table",
schema="promotions",
tags = ["staging", "promotions"]
) }}
WITH base_table AS (
SELECT
*,
{{ timestamp_to_date('time') }} as day
FROM supershy.users u
INNER JOIN supershy.events e
ON u.id = e.user_id
), most_used_features AS (
SELECT
name,
day,
COUNT(*) AS usage
FROM base_table
WHERE day >= 'Jan-1-2020'
AND day <= 'May-28-2021'
GROUP BY name, day
ORDER BY day DESC
) SELECT * FROM most_used_featuresThe chart below can be found in the Dashboards tab. Note that the visualization can be produced by highlighting the SQL statement and hitting Add to dashboard as demonstrated above.
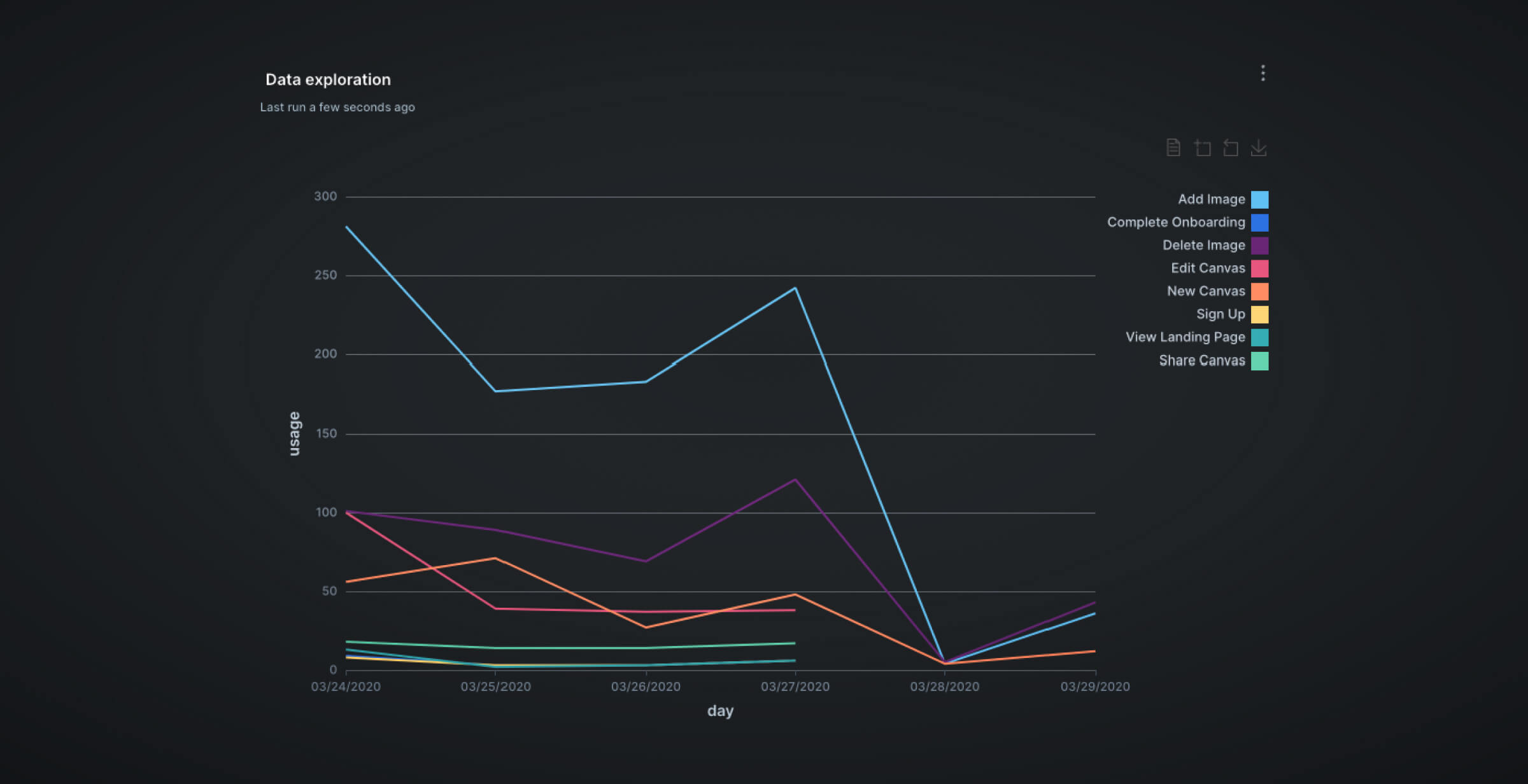
Evaluate your custom tests
The reason why we use custom tests is to catch test cases that aren’t covered by the generic tests. dbt tests are macros that test a certain condition and if the result is not null, then it fails.
A test that we often need but is cumbersome to run manually is the duplicate test. This test checks if there are duplicate rows in the table.
{% test check_duplicates(model, column_name, num_cols) %}
select distinct *
from {{ model }}
{{ dbt_utils.group_by(num_cols)}}
having count(*) > 1
{% endtest %}Note that [dbt_utils](https://github.com/dbt-labs/dbt-utils#group_by-source) is a package with a suite of useful macros and it is available for public use. The macros within are comprehensive and can save you even more time as you do not have to reinvent the wheel.
In PopSQL, we test by simply hitting Test:
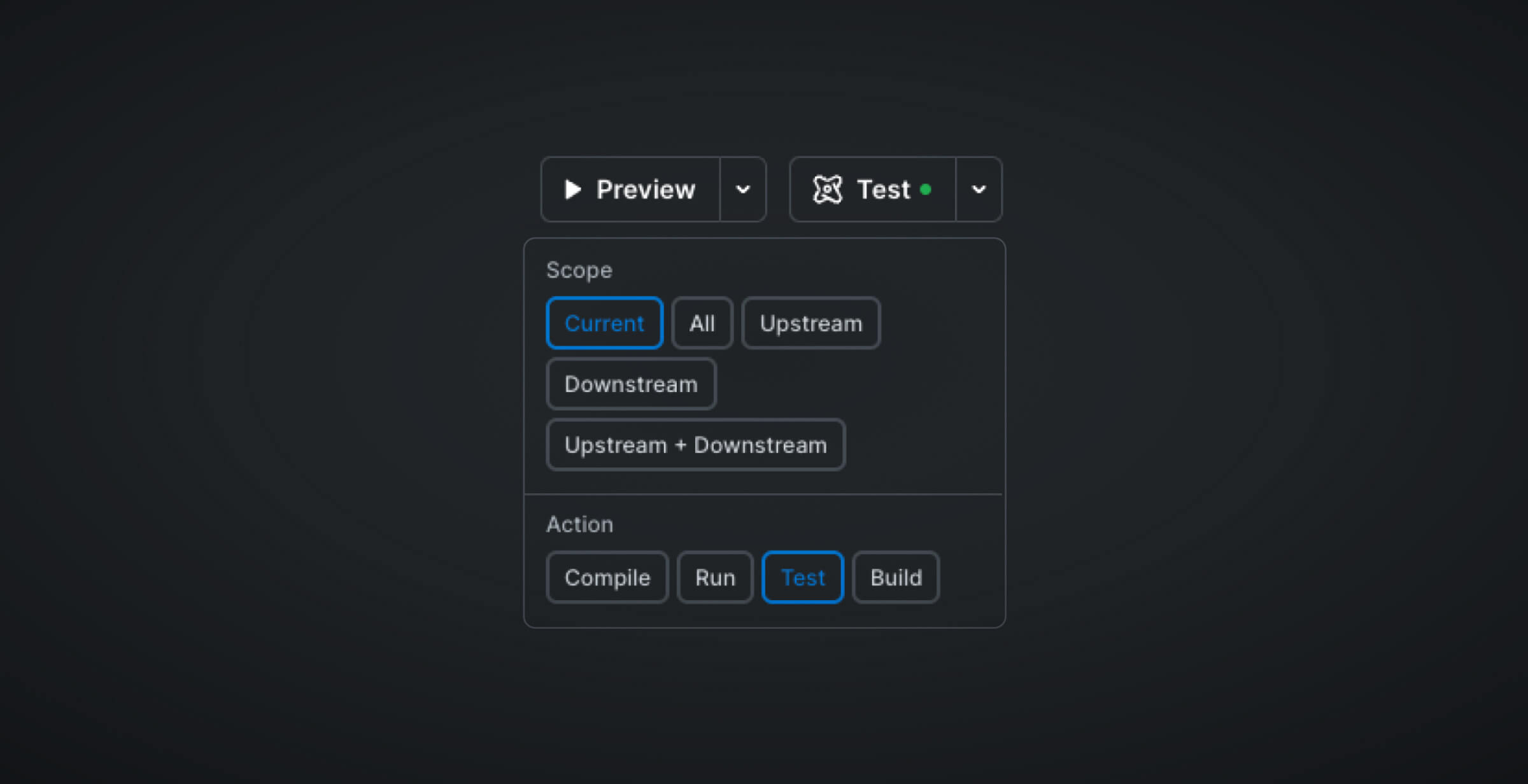
PopSQL will log any failures either in the compilation or at runtime, as shown below:
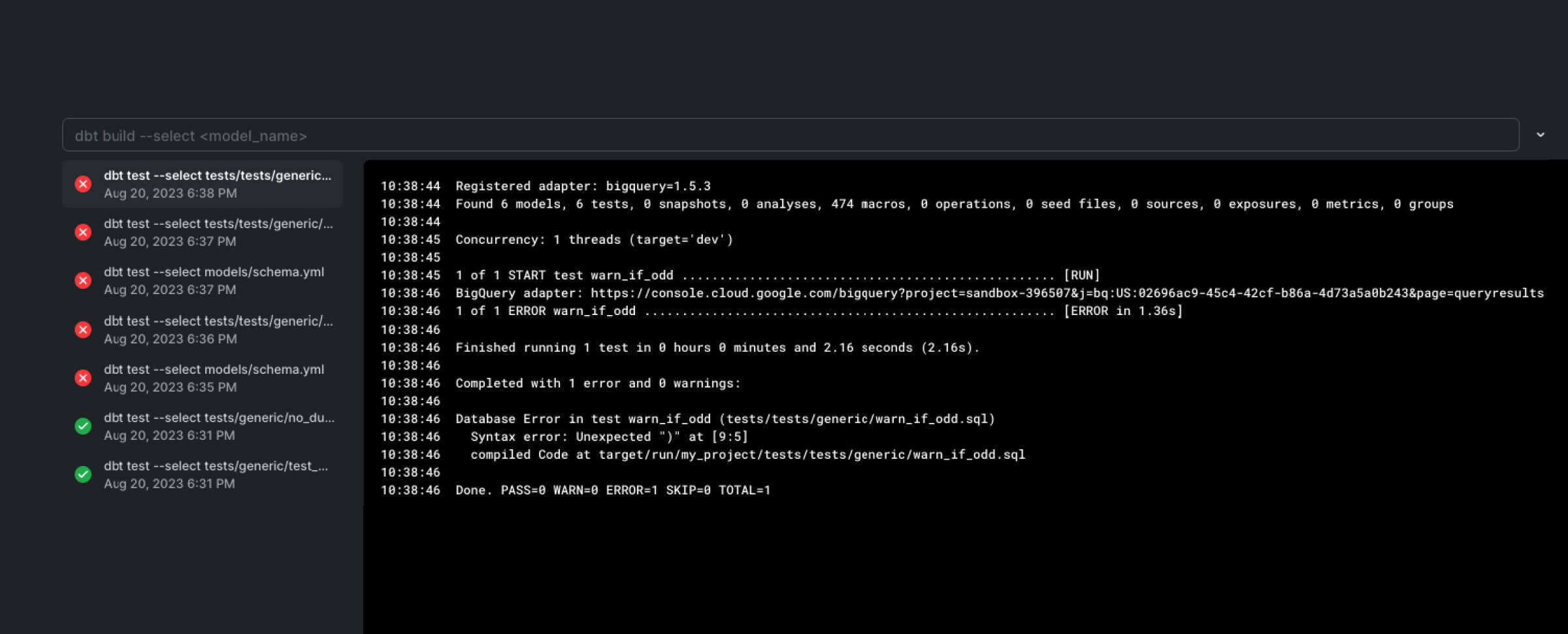
In less than 5 minutes, we have verified that our macro is working as expected. We can now use it as part of our pipelines.
Manage schema changes in source data efficiently
Changes in source data are inevitable as businesses are constantly evolving. However, this translates to additional overhead for developers. You need to update your models accordingly to prevent any future accidents, such as schema mismatches and inconsistent data. Normally, business-side users are tasked with the responsibility of communicating any source changes. However, in PopSQL, you can actually set up notifications for schema changes.
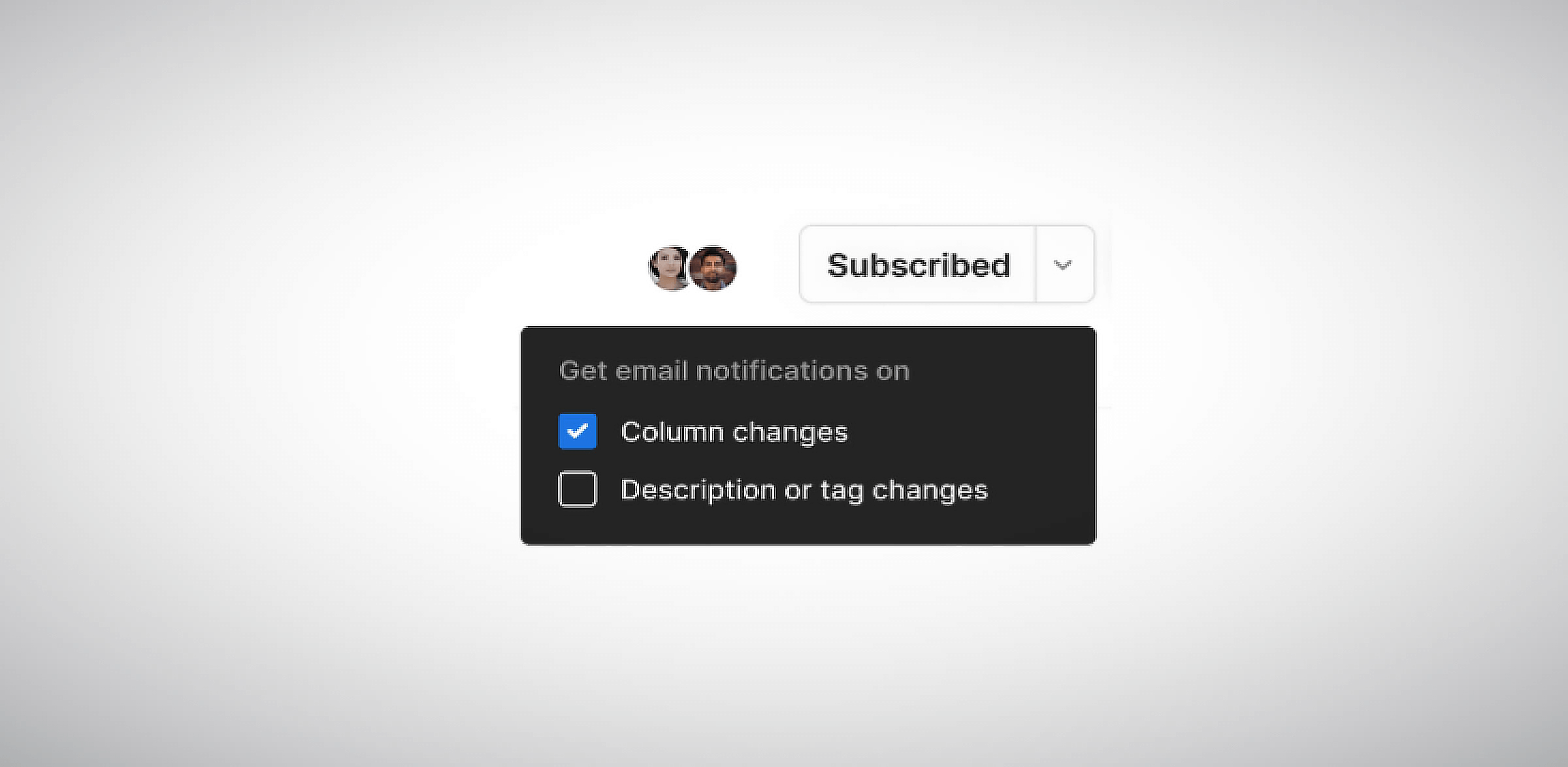
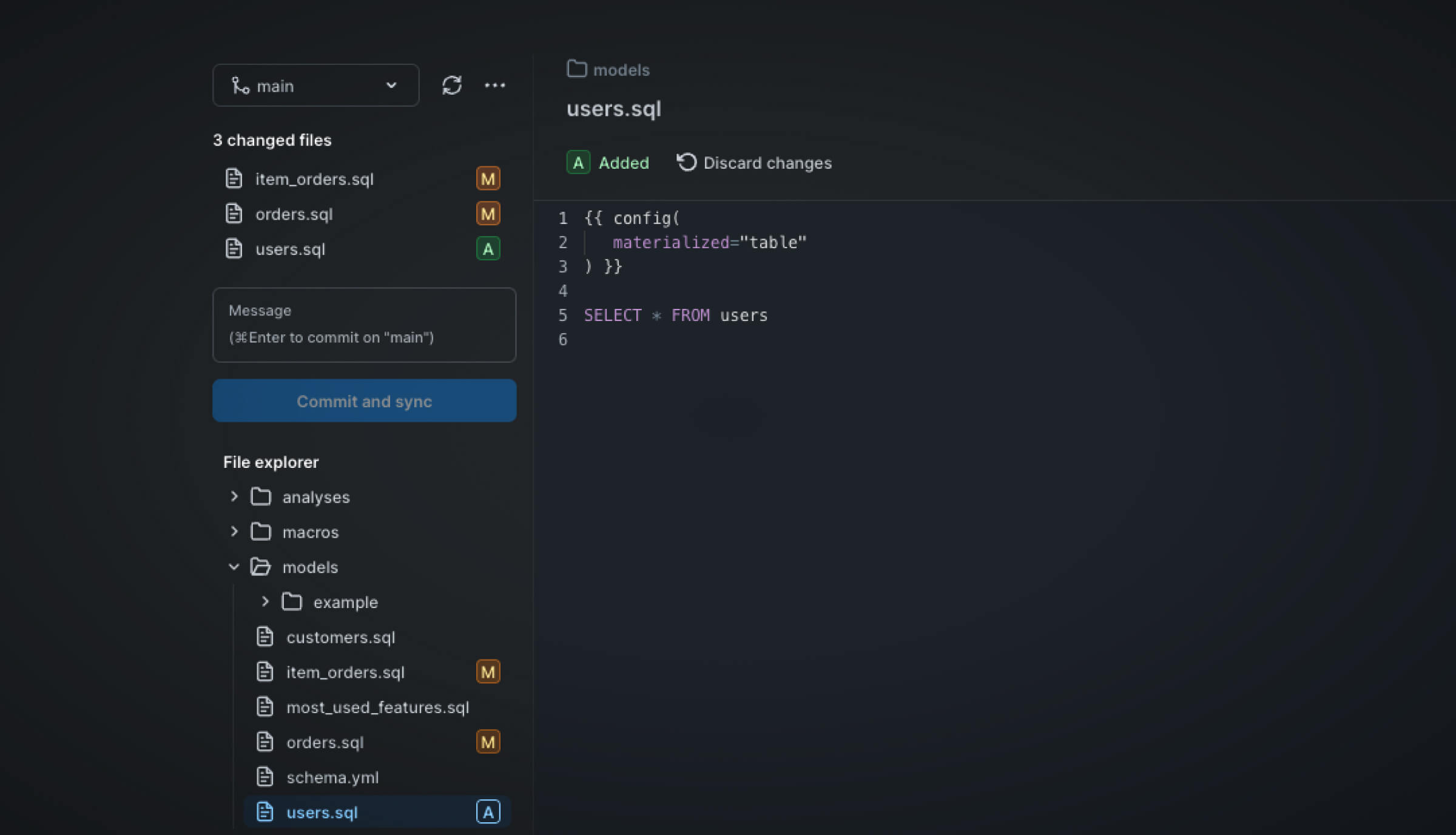
Then, to modify your model, simply do so in the PopSQL app and commit your changes to your repository.
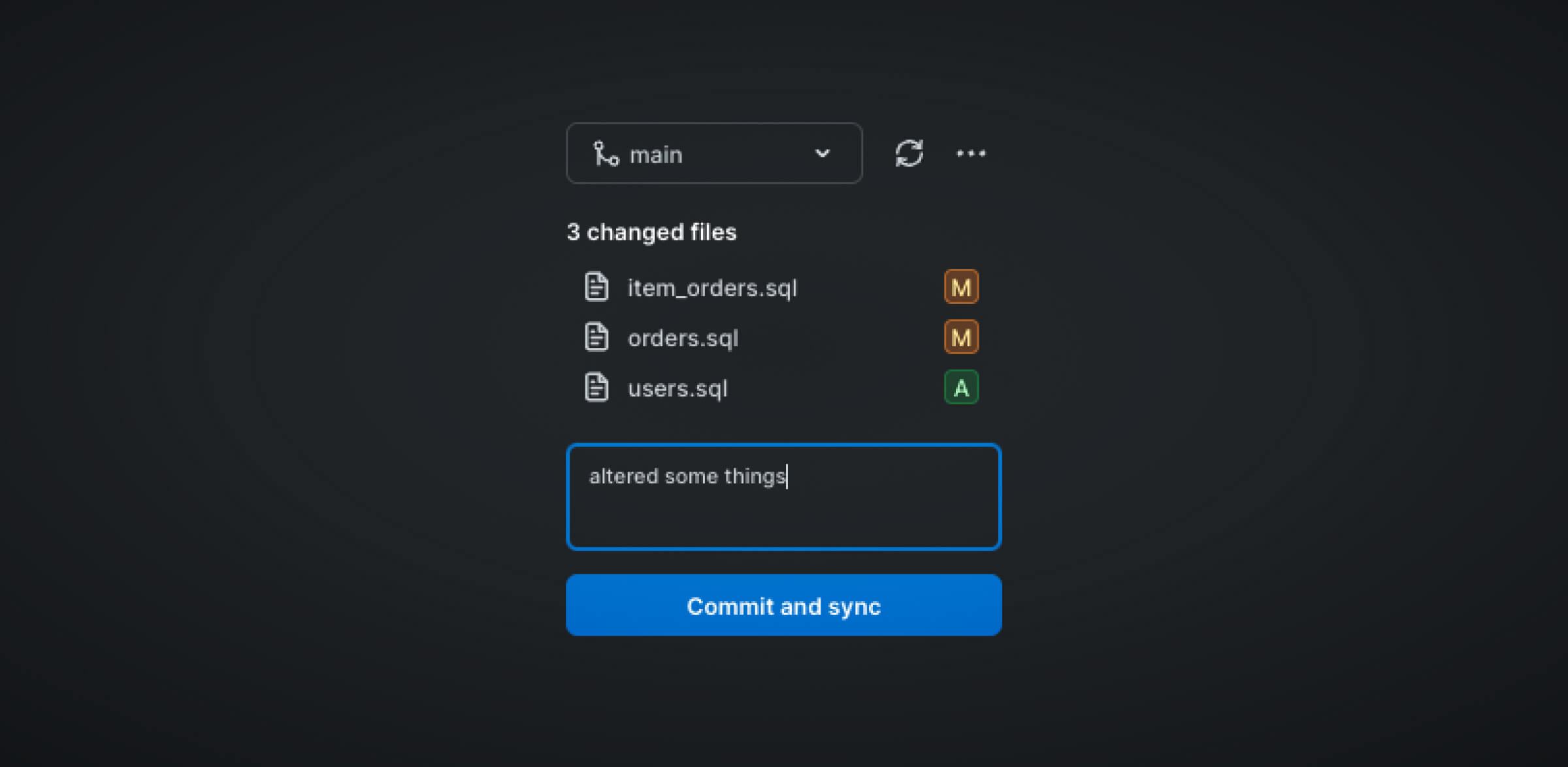
Implement version control
PopSQL has a native integration with Git for dbt. Meaning, that version control is streamlined similar to VSCode. Version control is important for keeping code up-to-date and implementing new features and fixes. If you are not already using a version control system, you can start with Github.
Conclusion
dbt on its own is a powerful tool. But it is not always easy to work with dbt due to constant context switching between terminal, code editor, and SQL editor. PopSQL brings it all for you through its powerful SQL editor that lets you manage your entire dbt development in one place. Its streamlined nature, using PopSQL for dbt development, shaves off hours (and sometimes days) of development time (and frustration).
With PopSQL, you can improve your dbt development experience radically as you:
- Conduct data exploration and create dashboards
- Test your model queries on PopSQL
- Test your macros on PopSQL
- Test your custom tests on PopSQL
- Update source models every time there is a change in source data
- Implement version control
Try the dbt core beta today by signing up here.

{kind=link}