Snowflake vs Redshift: Key differences and comparison

As businesses increasingly shift towards cloud-based data warehousing solutions, two prominent platforms, Snowflake and Amazon Redshift, have emerged as popular choices.
This article delves into the differences between Snowflake and Redshift, including performance, pricing, use cases, and more. Exploring the syntax variations, reasons to use Snowflake over Redshift, and how Snowflake differs from Redshift in various aspects will assist you in making an informed decision about the ideal cloud data warehousing platform that aligns with your organization's specific needs.
Snowflake: Overview
Snowflake is a cloud-based data warehousing platform designed to store, manage, and analyze extensive amounts of data. It provides a scalable, flexible, and efficient data storage and processing environment to address the challenges of traditional data warehousing solutions.
Snowflake’s architecture is designed from the ground up for the cloud, enabling it to harness the cloud's scalability, flexibility, and cost-effectiveness. This design empowers Snowflake to provide high-performance analytics and data processing capabilities.
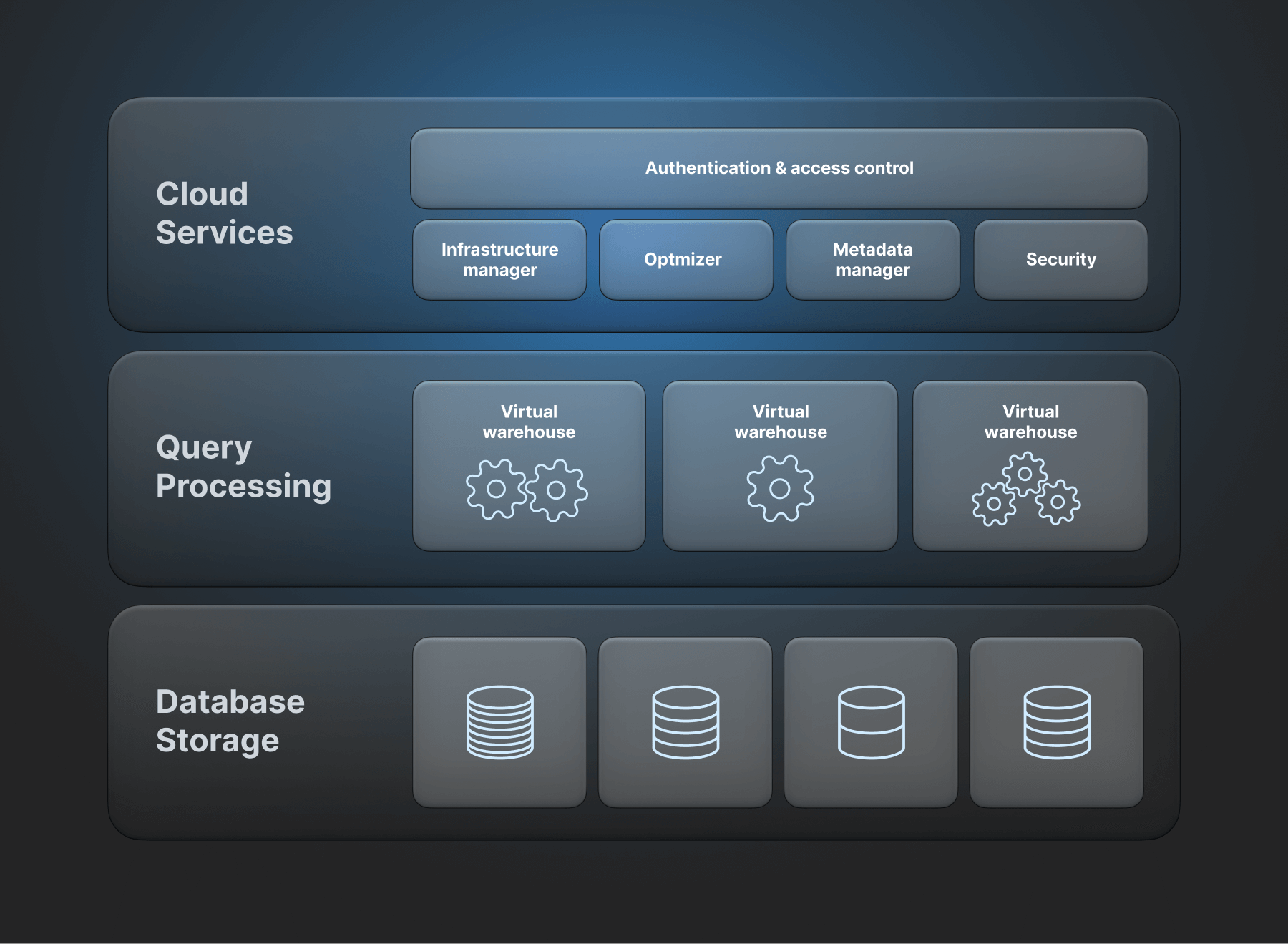
Snowflake: Features
Snowflake is equipped with various modern data warehousing features facilitating seamless data management, advanced analytics, and effortless collaboration. Following are some of the key features that set Snowflake apart:
Elasticity: You might often find your data teams struggling with managing the scalability of your data warehousing infrastructure. They face the dilemma of whether to provision enough resources to handle peak workloads or avoid over-provisioning during periods of low activity, which can lead to unnecessary costs.
Snowflake addresses this challenge by offering a single elastic performance engine. This ensures seamless scaling of compute and storage resources, automatically adjusting to match the workload demands. This elasticity not only optimizes performance during peak usage times but also reduces costs by dynamically scaling down resources during periods of low activity, mitigating the need for manual resource management.
Built-in SQL interface: Writing and executing SQL queries can be error-prone and time-consuming for users. Inefficient query writing can lead to performance bottlenecks and delays in obtaining valuable insights.
Snowflake simplifies this process by providing a user-friendly SQL interface with autocomplete features. This enhances query efficiency and reduces errors, enabling users to write and execute queries more effectively.
Semi-structured data format support: You may find your organization grappling with the complexities of handling diverse data types, including semi-structured formats like JSON, Avro, and Parquet. Integrating such data into analytics processes can be challenging and time-consuming.
Snowflake natively supports semi-structured data formats, simplifying data ingestion and analysis. This capability streamlines the integration of various data types, enabling organizations to gain deeper insights from their data without the need for complex data preprocessing.
Multi-cluster compute: Managing concurrent execution of queries in a data warehouse can be a significant challenge. Without a robust architecture, query performance can degrade when multiple users or workloads are active simultaneously.
Snowflake functions on a multi-cluster architecture, enabling concurrent query execution to improve query performance and overall system efficiency.
Hybrid database architecture: Data warehousing systems often rely on either row-based or column-based storage, making it challenging to optimize for both transactional and analytical workloads.
Snowflake supports a hybrid database architecture, combining both row-based and column-based storage techniques. This provides businesses the flexibility to efficiently manage varying workloads within a single platform.
Cross-cloud governance controls: Managing data governance, access, and security across multiple cloud providers can be complex and pose risks to data integrity and compliance.
Snowflake offers robust governance controls to enable efficient data access, permissions, and security management, ensuring data integrity and compliance in a multi-cloud environment.
Snowflake: Advantages
As a modern data warehousing platform, Snowflake offers several key advantages for organizations seeking powerful data management solutions, including:
- Pay-per-usage pricing: Snowflake's pricing model follows a pay-as-you-go approach, allowing organizations to pay only for the resources they consume.
- Centralized, fully-managed data management: Snowflake's fully managed service eliminates the need for organizations to invest in dedicated IT resources for database maintenance and management. Snowflake takes care of routine tasks such as backups, software updates, and optimizations, ensuring a hassle-free experience for data teams.
- High availability: Snowflake's architecture is built for high availability, ensuring data accessibility and query responsiveness at all times. With multiple data centers and redundant storage, Snowflake provides robust failover capabilities, minimizing the risk of data loss and downtime.
- Scalability: Snowflake's elastic scaling enables seamless resource expansion or contraction based on demand. Organizations can dynamically adjust compute and storage resources to handle fluctuating workloads, ensuring consistent performance even during peak usage.
- Secure data sharing and collaboration: Snowflake's native data sharing features enable secure collaboration and data sharing with external partners, customers, or other departments without data duplication. This streamlined sharing process is protected according to industry standards under Snowflake's built-in security and compliance features.
- Easy onboarding and smooth learning curve: Snowflake's SQL-based architecture offers a distinct advantage for individuals and teams familiar with SQL, which is a widely used query language in the data industry. If you have prior experience with SQL (as is the case for most data professionals), transitioning to Snowflake becomes remarkably straightforward. The similarities in SQL syntax significantly reduce the learning curve, allowing for an easy onboarding process. As a result, your teams can quickly adapt to Snowflake's architecture and leverage its powerful cloud data warehousing capabilities with minimal training and disruption. This seamless integration of SQL familiarity makes Snowflake an attractive choice if you are looking to expedite your migration to the cloud and enhance data management efficiency.
Snowflake: Disadvantages
Despite the many advantages Snowflake offers, it is essential to be mindful of the challenges that come with its usage. Some of its drawbacks include:
- Cost variability: While Snowflake offers a pay-as-you-go model, it can become costly as usage scales. The potential for spiraling costs can be a significant disadvantage, particularly for organizations with fluctuating workloads. Several data warehousing solutions take advantage of this, and position themselves as more cost-effective alternatives to Snowflake, emphasizing lower pricing structures without compromising on performance.
- Limited integration with on-premise businesses: One potential drawback of Snowflake is its cloud-native architecture, which may present challenges for businesses heavily invested in on-premise infrastructure. Integrating Snowflake with existing on-premise systems and workflows might require additional planning and effort.
- High data migration costs for large datasets: For organizations with massive datasets stored in on-premise systems, migrating data to Snowflake can be a resource-intensive and costly process. Transferring large volumes of data over the internet to the cloud can result in significant data migration expenses.
Snowflake: Use cases
In today's world Snowflake is an integral part of modern data stacks - be it consumer product companies like PepsiCo or Adobe, a vast variety of big and small players use Snowflake. Here are some of the use cases that Snowflake offers:
- Data warehousing: By design, Snowflake is a data warehousing platform for structured and semi-structured data management. Its cloud-native approach, elastic scaling, and fast query performance enable efficient data warehousing operations.
- Data exploration: Snowflake's support for semi-structured data formats makes it well-suited for connecting to data lakes, such as Amazon S3 or Azure Data Lake Storage. These integrations facilitate easy data exploration and analysis of raw and unstructured data.
- BI and analytics: Snowflake offers powerful analytical features that enable organizations to perform advanced BI and analytics. Its high concurrency and fast data retrieval allow them to generate interactive dashboards, reports, and visualizations, empowering data-driven decision-making in their organization.
- Ad hoc use cases: Snowflake is a flexible data management tool, suitable for ad hoc data analysis and exploration use cases. It enables users to quickly run queries on diverse datasets, extract insights, and experiment with data for improved business operations.
- Machine learning: Snowflake's integration with machine learning-platforms and libraries, and native support for semi-structured data allows organizations to perform advanced machine learning tasks. Snowflake's scalable infrastructure allows users to train ML models and collaborate on model results to gain valuable insights.
When to use Snowflake?
Snowflake's modern data analytics and storage capabilities suit several use cases. Here are some scenarios where Snowflake excels:
- Data variety and complexity: When your data includes diverse types and structures, such as semi-structured data (JSON, Avro, Parquet), Snowflake's native support simplifies ingestion and analysis, allowing you to handle complex datasets effectively.
- Scalability demands: If your business frequently experiences fluctuations in data volume and requires a solution that can automatically scales resources, Snowflake's elasticity ensures smooth performance even during periods of rapid growth.
- Agile data management: Organizations requiring flexible infrastructure to handle dynamic usage trends or rapidly changing datasets can use Snowflake's cloud-native environment for adaptable and efficient data management
- Real-time analytics: For organizations seeking fast query performance and real-time insights, Snowflake's optimized architecture and capabilities make it a reliable choice to support data-intensive analytical workloads.
Redshift: Overview
Amazon Redshift is a cloud-based data warehousing platform that Amazon Web Services (AWS) offers. It is a fully-managed service designed on a parallel processing architecture to handle large-scale analytics workloads, primarily for structured datasets.
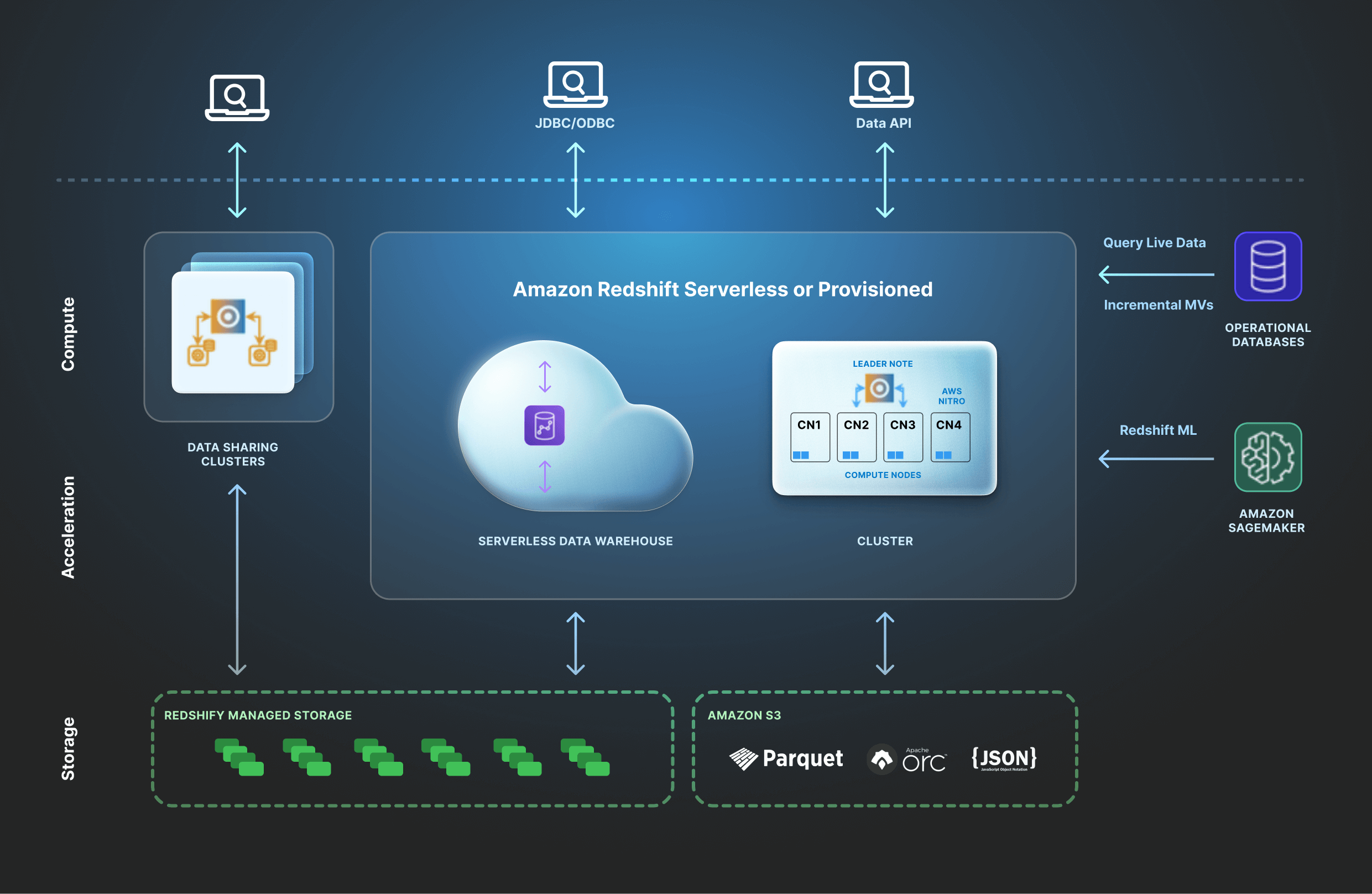
Redshift: Features
Columnar data storage: Traditional row-based storage can lead to suboptimal query performance and increased storage costs, especially when dealing with large volumes of data.
Redshift employs columnar data storage, optimizing data retrieval and query performance. By storing data column-wise, it reduces the data scanned during queries, resulting in faster query execution and cost-effective storage.
Seamless integration with AWS ecosystem: Organizations often use a range of AWS services alongside their data warehousing solution. Integrating these services can be complex and time-consuming.
As part of the AWS ecosystem, Redshift seamlessly integrates with various AWS services, creating a unified data infrastructure. This simplifies data workflows, enables efficient data sharing, and allows organizations to leverage the broader AWS ecosystem for advanced analytics and machine learning capabilities.
Massive Parallel Processing (MPP) architecture: Handling large-scale data processing efficiently can be a significant challenge, especially when dealing with complex queries and extensive datasets.
Redshift's MPP architecture distributes data and query loads across multiple nodes, facilitating parallel execution of queries. This architecture effectively addresses the challenge of large-scale data processing by ensuring rapid query performance, even with extensive datasets.
Redshift ML: Incorporating machine learning into data warehousing processes often involves complex integrations and data transfers between different platforms.
Redshift ML simplifies machine learning integration by allowing users to construct, train, and deploy machine learning models directly within Redshift, leveraging Amazon SageMaker. This streamlines the machine learning workflow, eliminating the need for integrating with ML tools.
Streaming data ingestion: Real-time data analysis requires the ability to ingest and process streaming data from various sources effectively.
Redshift supports streaming data ingestion, enabling organizations to process and analyze data as it streams in. This feature enhances real-time analytics capabilities and ensures that organizations can derive insights from streaming data sources.
Data querying and exporting to and from Data Lakes: Integrating and querying data stored in data lakes, including Amazon S3, can be complex and require specialized tools due to the diverse and unstructured nature of the data typically found in data lakes.
Redshift simplifies data querying and export to and from data lakes, such as Amazon S3. Users can leverage Redshift's powerful SQL capabilities to access and analyze data stored in data lakes directly within the data warehousing environment. This simplifies data processing and analysis workflows, eliminating the need for complex data lake integration.
Data compression: Efficiently managing storage costs can be challenging when dealing with large datasets due to substantial storage requirements. Additionally, optimizing query performance can be difficult, as vast volumes of data may lead to increased query processing times.
Redshift employs advanced data compression methods to minimize storage costs and requirements while simultaneously improving query performance.
Redshift: Advantages
Following are some of the key benefits of using Redshift:
- AWS services integration: As part of the Amazon Web Services ecosystem, Redshift seamlessly integrates with other AWS services. This integration allows organizations to leverage a wide range of complementary AWS tools for data storage, processing, and analysis, creating a cohesive and efficient data infrastructure.
- Automated backups and maintenance: Redshift provides automated backup and maintenance, reducing the administrative burden on users. Regular backups ensure data durability and availability, while automated maintenance tasks, such as software updates and optimizations, keep the cluster running smoothly.
- Automated data copying from Amazon S3: Redshift simplifies data ingestion by enabling automated data copying from Amazon S3, a scalable data storage solution. This feature streamlines loading data into Redshift, making it easier for organizations to analyze large datasets inside Redshift without manual intervention.
- Cost-effectiveness: Redshift brings together on-demand resource utilization and AWS's cost-efficient infrastructure in its platform. This allows users to get maximum value from their data analytics initiatives while maintaining cost control and budget predictability.
- High-performance architecture: Redshift's distributed architecture allows concurrent data and query processing across multiple nodes. This allows Redshift to efficiently handle large-scale analytics without compromising scalability.
- Horizontal scalability: Redshift offers horizontal scalability, allowing organizations to add or remove nodes to meet fluctuating data processing demands. This elasticity ensures that Redshift can adapt to varying workloads, providing optimal performance during peak periods and cost efficiency during off-peak times.
Redshift: Disadvantages
Redshift, as a data warehousing solution, comes with a host of advantages, but like any technology, it has its limitations that users should keep in mind when using the platform:
- Time-consuming data ingestion: The process of ingesting and loading large datasets into Redshift can be time-consuming, especially when dealing with massive volumes of data. This initial data loading phase can impact the speed at which users can begin querying and analyzing their data.
- Limited decoupling of storage and compute: Redshift offers limited decoupling of storage and compute resources. This means that when scaling compute resources, organizations may also need to scale storage simultaneously, potentially affecting cost optimization and resource allocation.
- Platform dependency: Redshift is exclusively available on the AWS platform causing vendor lock-in. While this is advantageous for organizations already utilizing AWS services, it can be a limitation for those with a multi-cloud or different cloud provider strategy, as it requires a commitment to the AWS ecosystem.
- Training and learning curve: One disadvantage of Amazon Redshift lies in the training and learning curve required for data teams transitioning to this platform. While it offers powerful data warehousing capabilities, Redshift has its own unique features and query optimization techniques that may differ from traditional data warehouses. This means that if your team is familiar with other data warehousing systems, you may need to invest time and resources in acquiring expertise in Redshift-specific practices. This could potentially slow down initial adoption and impact productivity until proficiency is achieved.
Redshift: Use cases
Redshift offers a versatile and robust platform for various data warehousing and analytics use cases. Some key scenarios where Redshift proves to be highly valuable include:
- Enterprise data warehousing: Redshift is efficient at handling and storing vast amounts of structured data for effective enterprise data warehousing. Its MPP architecture makes it highly suitable for large-scale data management and processing for diverse business operations in one tool.
- Internal BI and analytics: Organizations rely on Redshift as a central data repository to power their internal business intelligence and analytics processes. The platform's ability to ingest, transform, and analyze data at scale enables business users to derive actionable insights and make data-driven decisions, fostering business growth and efficiency.
- Data exploration: Redshift also serves as a data exploration platform enabling data analysts and scientists to dig deep into vast datasets and discover meaningful patterns and trends. Its fast-query feature allows for quick iterations and hypothesis testing, accelerating exploration and uncovering valuable insights.
- Machine learning: Redshift's ML feature allows data scientists to preprocess and prepare data in Redshift and then use SageMaker to build, train, and deploy machine learning models. With this unified workflow, Redshift empowers organizations to leverage ML algorithms and derive predictive insights from their data inside Redshift.
When to use Redshift?
Redshift is a powerful data warehousing tool that excels in several use cases, making it a compelling choice for organizations facing specific data challenges. Here are some of the scenarios where Redshift shines:
- Already using AWS services: For organizations heavily invested in the AWS ecosystem, Redshift seamlessly integrates with other AWS services, making it a natural choice for streamlined data processing and analytics within the AWS environment.
- Heavy querying load: Redshift's MPP architecture enables it to handle heavy querying workloads with ease. Organizations dealing with complex analytical queries on vast datasets can rely on Redshift's high-performance capabilities for fast and efficient results.
- Complex analytics on large datasets: Redshift is particularly well-suited for complex analytics on large datasets, including data measured in petabytes, such as behavioral data analytics. As the volume of data grows, Redshift's value as a powerful and cost-effective database proposition increases.
| Snowflake | Redshift | |
| Architecture | Multi-cluster with decoupled commute and storage | Massive Parallel Processing with limited resource decoupling |
| Cloud Integrations | Internal & external databases (Amazon S3, Google Cloud, Azure Blob) | Internal Amazon databases only (S3, RDS) |
| Data Storage | Hybrid (Columnar and Row-based) | Columnar storage |
| Data Types | Structured + Semistructured (CSV, JSON, Avro, ORC, Parquet, or XML) | Primarily structured (TextFile, SequenceFile, RCFile, RegexSerDe, ORC, Grok, OpenCSV, lon, JSON) |
| Querying Language | SQL | SQL |
| Server Management | More hands-off, serverless management | More hands-on, self-management |
| Performance | Real-time analytics on high concurrency, varying workloads | Fast-querying of for streaming analytics of large datasets |
| Ease-of-use | User-friendly, Low learning curve | User-friendly, Steeper learning curve |
| Pricing Model | Usage-based, On-demand | On-demand based on number of nodes |
Key similarities and differences between Snowflake and Redshift
What do Snowflake and Redshift have in common?
When comparing Snowflake and Redshift, it's important to recognize that these two cloud-based data warehousing platforms exhibit several core similarities. Key areas where Snowflake and Redshift converge include
1. Cloud-native architecture
Both Snowflake and Redshift embrace a cloud-native approach, positioning themselves as fully cloud-based solutions. This architecture leverages the power of cloud computing, enabling dynamic resource allocation and offering a scalable foundation for data storage and processing.
2. Syntax
Both Snowflake and Redshift support ANSI SQL, ensuring compatibility with existing SQL queries and tools. This common syntax simplifies migration and minimizes the learning curve for users familiar with standard SQL.
3. Fully-managed services
Snowflake and Redshift alleviate the operational burden on users by offering fully-managed services. The platforms take care of essential maintenance tasks, updates, and backups, empowering data professionals to focus on data analysis rather than infrastructure management.
4. Elastic scaling
Recognizing the importance of adaptability to fluctuating workloads, Snowflake and Redshift provide elastic scaling capabilities. This ensures that resources can expand or contract dynamically based on demand, ensuring optimal performance during high-traffic periods and cost-efficiency during periods of low activity.
5. Data security
Both Snowflake and Redshift prioritize data protection by implementing industry-leading practices. These data security measures include data encryption, access controls, and network security protocols to ensure protection and compliance with industry regulations. By adhering to these stringent security practices, both Snowflake and Redshift provide their users with the confidence that their critical data is well-protected, meeting the highest security standards in the cloud-based data warehousing domain.
What is the difference between Snowflake and Redshift?
Despite their shared fundamental features and characteristics, Snowflake and Redshift also exhibit significant differences. These distinctions are crucial in determining the most suitable platform for specific data warehousing and analytical needs. Here are the key differences between Snowflake and Redshift:
1. Architecture
Snowflake follows a multi-cluster architecture, separating compute and storage, allowing independent scaling of each component. This architecture provides elasticity and optimal resource utilization, ensuring efficient performance for varying workloads.
On the other hand, Redshift utilizes a Massively Parallel Processing (MPP) architecture, distributing data and query processing across multiple nodes. While this architecture delivers high-performance query capabilities, it may require manual tuning for specific use cases.
2. Data structure
Snowflake natively supports semi-structured data formats, such as JSON, Avro, and Parquet, making it ideal for handling diverse data types and structures. This native support simplifies data ingestion and analysis, enhancing flexibility in dealing with complex datasets.
In contrast, Redshift is primarily designed for structured data formats, such as OpenCSV, TextFile, and SequenceFile. It is optimized for handling traditional relational data stored in tables with fixed schemas. Handling semi-structured data formats, like JSON and Avro, in Redshift might require additional preprocessing before ingestion and analysis.
3. Data collaboration
Snowflake offers native data-sharing capabilities, enabling secure data sharing with external partners, customers, or other departments without data duplication. This feature streamlines collaboration and enhances data accessibility across the organization.
While Redshift also supports data sharing, it may involve more manual effort and data movement than Snowflake's native sharing capabilities.
4. User interface
Snowflake provides an intuitive and user-friendly web-based interface, simplifying data management and query execution. This user interface allows users to focus on data analysis rather than dealing with complex configurations.
In contrast, Redshift, being part of the AWS ecosystem, integrates with the AWS Management Console, making it familiar and easy-to-use for users already using other AWS services.
5. Security
Snowflake offers built-in security features, including end-to-end data encryption, role-based access controls, and multi-factor authentication. These robust security measures ensure data protection and compliance with industry standards.
On the other hand, Redshift provides customizable security options, allowing users to configure security settings based on their specific requirements.
6. Performance
Snowflake's multi-cluster architecture automatically scales resources, maintaining consistent query performance even during high-concurrency workloads. This scalability ensures that the platform can handle varying demands efficiently.
In comparison, Redshift's MPP architecture delivers high-performance querying capabilities. Redshift distributes data and query processing across multiple nodes, allowing it to parallelize queries and process large data volumes simultaneously. Resultantly, Redshift delivers fast query execution for handling complex analytical workloads.
7. Snowflake vs. Redshift: Customization and flexibility
Snowflake provides a high degree of flexibility in areas, such as data modeling, access control, and query optimization. However, one notable limitation is the inability to customize compute node types. Users cannot choose different hardware configurations for different compute clusters. Despite this, Snowflake compensates with its automatic scaling capabilities, allowing seamless adjustments based on workload demands without the need to manage hardware specifications
Amazon Redshift, on the other hand, offers more customizability of node types compared to Snowflake. Users have the flexibility to select different node types and storage capacity of nodes within a cluster, enabling them to fine-tune Redshift clusters for specific performance and cost requirements. This flexibility extends to query performance optimization, where Redshift provides various configuration options like Distribution Keys and Sort Keys, allowing users to have control over query execution.
8. Snowflake vs. Redshift: Machine learning
Snowflake offers integrations for various machine learning tools and libraries using its Snowpark ML APIs. These APIs enable users to transform data into ML-powered insights that they can collaborate on inside Snowflake. This empowers users to derive deeper insights from their data and apply machine learning algorithms efficiently.
On the other hand, Redshift's ML feature natively integrates with Amazon's SageMaker, which is a fully managed service provided by AWS that simplifies the process of developing, training, and deploying machine learning models at scale. This allows users to create and train SageMaker models using their data inside Redshift for various ML use cases.
Snowflake vs. Redshift: Total cost of ownership
Total cost of ownership is a critical factor in choosing a data warehousing platform, encompassing not only immediate costs but also various long-term financial considerations.
Immediate costs
Snowflake operates on a pay-as-you-go pricing model, where you pay for the resources you consume. Snowflake's pricing model provides flexibility, allowing organizations to align costs with actual usage. However, it's essential to emphasize that while this flexibility can be an advantage, organizations must exercise diligence in monitoring their usage to control costs effectively. Additionally, initial setup and data migration costs may apply, particularly if the migration is complex. Snowflake's variable pricing means that without careful oversight, costs can escalate, making it crucial for businesses to closely manage their expenses.
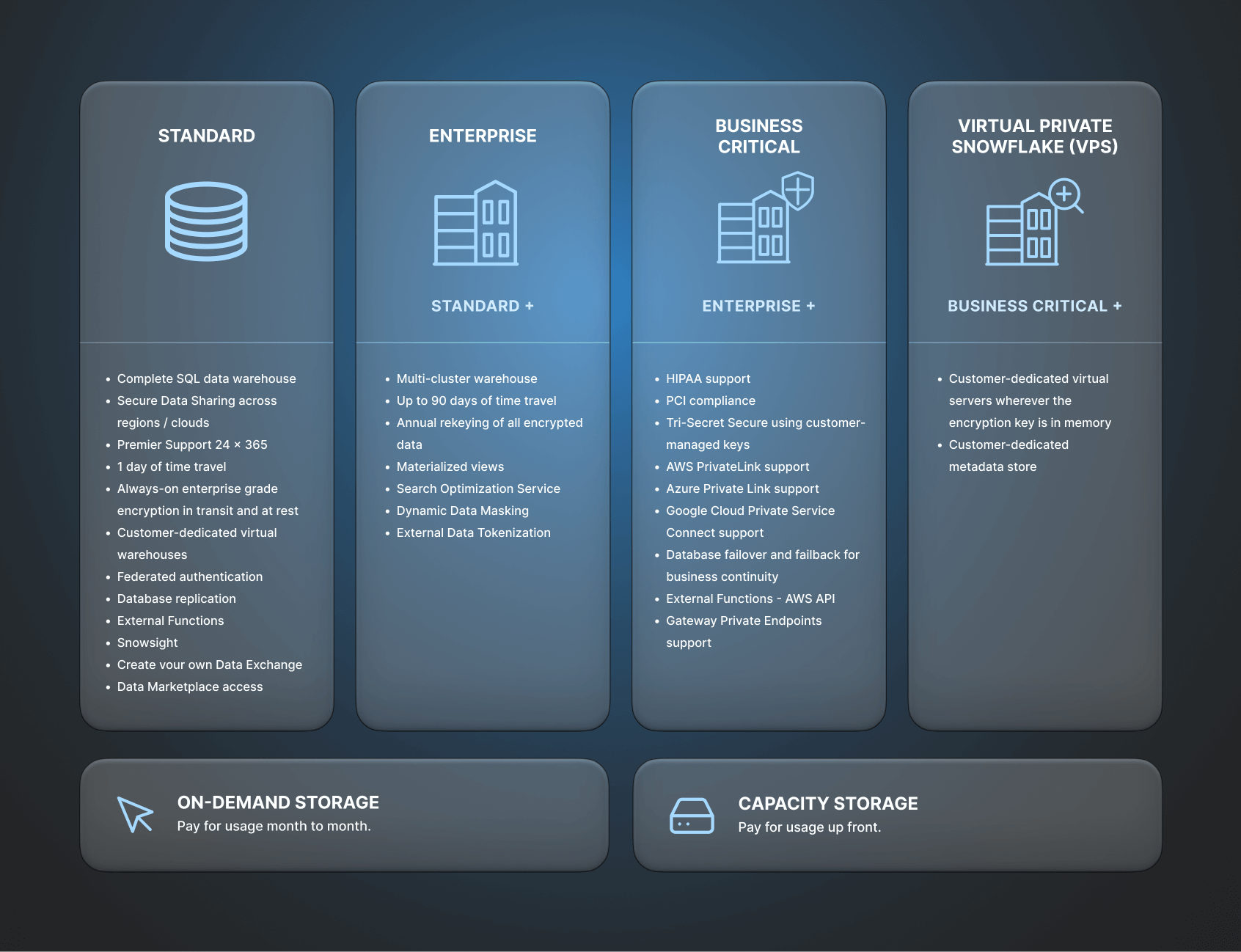
Redshift offers a range of pricing options, including on-demand, reserved instances, and concurrency scaling charges. This array of choices allows organizations to tailor their pricing model to meet specific needs and budget constraints. One notable advantage with Redshift is its transparency, which minimizes the risk of hidden costs. AWS provides clear pricing information, making it easier for organizations to budget accurately. While initial setup and data migration costs can vary, AWS offers tools and resources to streamline the migration process, helping businesses plan and execute migrations cost-efficiently.
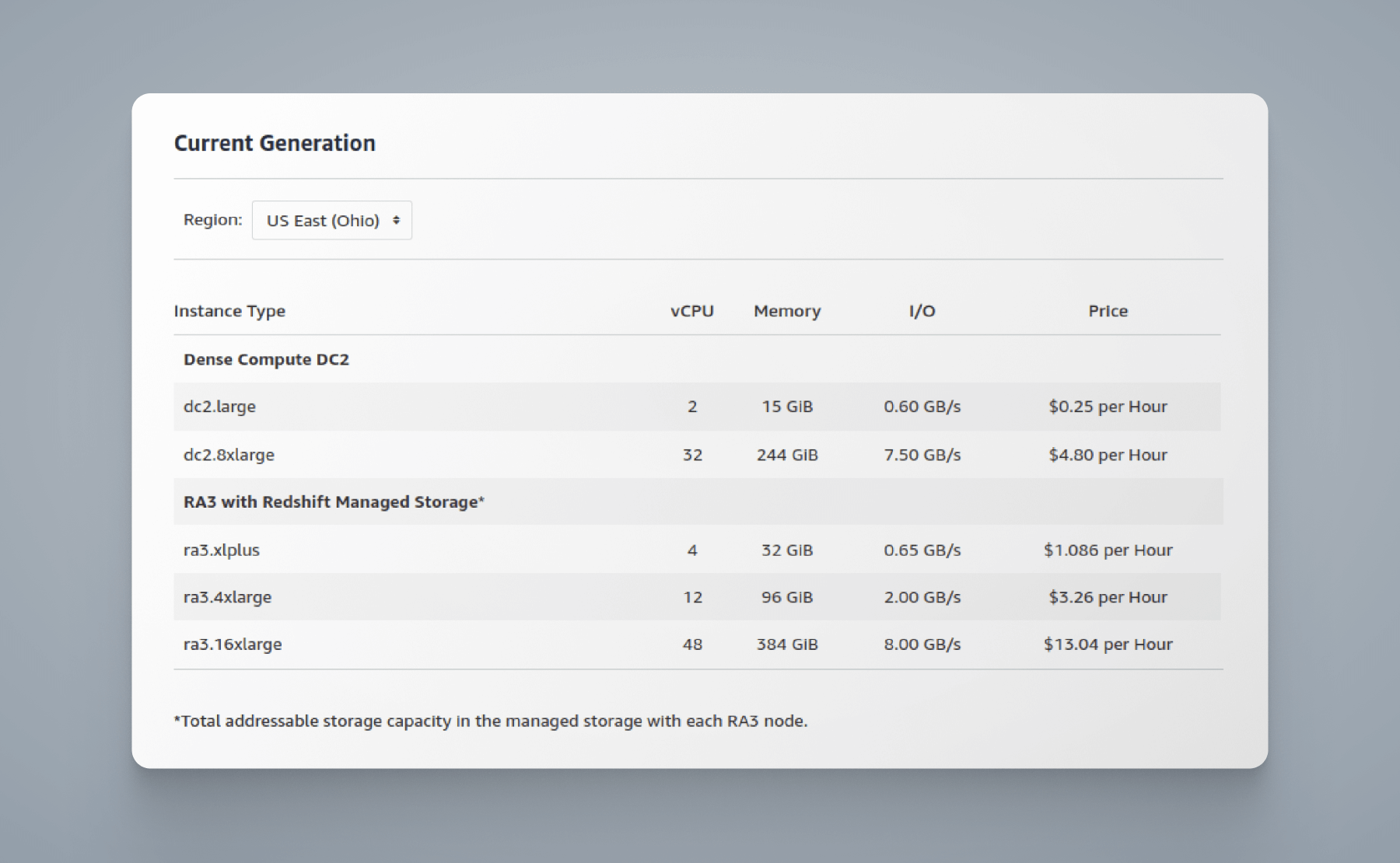
Personnel training
Snowflake is known for its ease of use, which may reduce the need for extensive personnel training. However, some training may still be necessary for administrators and data analysts to fully utilize its capabilities.
Redshift, being a hands-on platform, requires personnel to undergo training to maximize its capabilities and optimize data warehousing operations effectively. AWS offers extensive training resources and certification programs, which can be beneficial for personnel who need to manage and operate Redshift effectively.
Maintenance
Snowflake's managed service significantly reduces maintenance costs compared to traditional on-premises solutions. Since Snowflake handles hardware management, updates, and patching, organizations can allocate fewer resources and staff to these tasks. This translates to lower ongoing maintenance expenses compared to on-premises solutions.
Redshift is also a managed service, which means AWS takes care of infrastructure maintenance. However, it may require investment in skilled personnel or third-party tools to optimize the Redshift clusters and ensure efficient query performance, which could contribute to maintenance costs.
Potential downtimes
Snowflake warehouses are designed for rapid suspension and resumption, typically taking only milliseconds to perform these actions. Furthermore, users have the flexibility to configure warehouses to suspend automatically after a brief idle period, such as 5 minutes of inactivity, and then resume promptly when a query is issued. This agility in suspension and resumption allows for more granular control over costs and aligns well with use cases where responsiveness and cost optimization are paramount.
AWS maintains a robust infrastructure designed for high availability. However, as with any cloud service, occasional disruptions may occur due to factors beyond an organization's control, such as AWS service interruptions or regional issues. Redshift offers features like Multi-AZ (Availability Zone) deployments to enhance availability and minimize downtime.
Redshift also provides the option to pause or resume a cluster. When a Redshift cluster is paused, you don't incur compute charges during that period. However, it's essential to consider that the process of pausing and resuming a Redshift cluster takes approximately 15 minutes to complete. Downtime-related costs may include lost productivity during outages and potential expenses associated with disaster recovery planning or redundancy configurations.
Migration costs
Snowflake provides helpful tools and resources to streamline data migration processes, but organizations should anticipate certain costs associated with the migration. These costs can include data transfer expenses, particularly when moving large volumes of data to the cloud. Additionally, data may require transformation to align with Snowflake's structure, incurring data transformation costs. Downtime costs are also a consideration, as some data migration activities may necessitate temporary disruptions to data access and analytics operations, impacting productivity.
AWS offers tools like AWS Database Migration Service (DMS) and Schema Conversion Tool (SCT) to simplify the process of migrating data to Amazon Redshift. However, data transfer costs can accrue when transferring data to Redshift, especially if it involves substantial data volumes. Furthermore, data may need conversion or adjustments to fit Redshift's data model, incurring additional costs.
While both Snowflake and Redshift offer flexible pricing for most business needs, you should carefully evaluate your specific requirements, existing skill sets, and long-term data strategies to make an informed decision based on your financial constraints and objectives.
Snowflake vs. Redshift: Long-term considerations
Platform roadmap
Snowflake is an evolving data-warehousing platform that has been consistently expanding its feature set. With its focus on enhancing its data sharing capabilities, scaling options, and integration with other data tools, Snowflake commits to ongoing development and adaptability to meet your evolving business needs.
AWS continually invests in Redshift, adding new features and performance enhancements. They have a track record of incorporating customer feedback into their roadmap. Redshift's deep integration with other AWS services ensures it will continue to be a central component of AWS's data analytics and warehousing strategy.
Business growth
Snowflake's multi-cluster, shared data architecture inherently supports scalability, making it suitable for handling potential growth in data and users. Its cloud-agnostic approach means you can adapt to changing cloud provider preferences if necessary.
Redshift's automatic scaling and concurrency scaling features allow it to handle varying levels of workloads, accommodating growth in analytics demands. Being part of AWS also provides flexibility, as you can leverage other AWS services to adapt to changing requirements.
Migration
Snowflake offers features to facilitate data migration. Its built-in Snowpipe service can ingest data in real-time from various sources, making initial data migration more manageable. Additionally, Snowflake's SQL compatibility simplifies the migration of SQL-based workloads. The platform's cloud-agnostic nature also means you can move data between different cloud providers if needed, enhancing long-term flexibility.
Migrating to Amazon Redshift from on-premises or other cloud platforms is streamlined through AWS Database Migration Service (DMS) and the AWS Schema Conversion Tool (SCT). These tools help convert data warehouse schemas and automate the migration process. Redshift's compatibility with PostgreSQL makes it easier to migrate SQL-based workloads.
Long-term support
Snowflake's commitment to comprehensive support, including 24/7 technical assistance, extensive documentation, and a knowledge base, aligns seamlessly with its vision of bolstering businesses in the long run. With a service level agreement (SLA) that ensures uptime and query performance, Snowflake not only delivers immediate reliability but also lays the foundation for sustained success, empowering you to meet your long-term business objectives.
As an AWS service, Amazon Redshift benefits from the extensive support and resources of AWS. AWS offers various support plans, including premium support options with guaranteed response times. Redshift also has a track record of providing regular updates and improvements for long-term platform stability.
Snowflake vs. Redshift: External validation
Snowflake
- Ranked 2nd in Forbes Cloud 100, 2019.
- Announced as a Leader in Gartner's Magic Quadrant for Data Management Solutions 2019.
Redshift
- Recognized by Forrester’s Cloud Data Warehouse Report 2018 for the largest number of Cloud data warehouse deployments, with more than 6,500 deployments.
Snowflake vs. Redshift: User feedback
Snowflake
Users across various industries appreciate Snowflake’s ability to simplify engineering tasks, reduce maintenance burdens, and eliminate the need for excessive licenses and support. Snowflake's impact extends beyond cost efficiency, as users have found it instrumental in expanding their business intelligence capabilities and enhancing data-driven decision-making. Additionally, users who have harnessed its Data Cloud feature have reported seamless experiences with secure data sharing and collaborative scientific efforts. They consistently praise the platform for providing them with an efficient means of cooperation while maintaining the highest standards of data security and quality.
Redshift
Users have praised Amazon Redshift for its adaptability and scalability, facilitating a seamless transition to handling significantly increased data volumes. The platform's flexibility, combined with its performance, has proven instrumental in managing growing data demands. Additionally, organizations have reported substantial cost reductions since implementing Amazon Redshift, marking a significant achievement in optimizing operational expenses. Furthermore, users have acknowledged the invaluable support and collaboration from the AWS team throughout their transformation journey, ensuring the development and optimal performance of their BI and analytics platform.
How to choose between Snowflake or Redshift?
Choosing between Snowflake or Redshift for your data warehousing needs is an important decision for unlocking the full potential of your data.
Why use Snowflake over Redshift? Is Redshift better than Snowflake? Answering these questions requires careful consideration of various factors to ensure the selected platform aligns with your organizational requirements. Here are the key points to consider when making the decision:
Alignment with organizational budget and resources: It is important to evaluate the cost implications of both Snowflake and Redshift based on your budgetary constraints and data warehousing requirements.
Snowflake follows a pay-as-you-go pricing model, charging separately for compute and storage resources, which provides flexibility for cost optimization. On the other hand, Redshift's pricing is based on the number and type of nodes used. Analyzing the cost structure of each platform in the context of data volume and usage patterns will help determine the most economical solution for your organization.
Data structure and volume: The nature of your organization's data, including its structure and volume, plays a crucial role in platform selection. If your organization handles a variety of data types, including semi-structured data like JSON or Avro, Snowflake's native support for these formats may be more advantageous. On the other hand, if the data is primarily structured and relational, Redshift might be more suitable.
Alignment with performance requirements: It is critical to consider your organizational workload’s performance requirements when choosing between Snowflake and Redshift. Snowflake's architecture enables automatic scaling of resources, making it well-suited for handling varying workloads and high-concurrency scenarios efficiently. On the other hand, Redshift's MPP architecture provides fast querying capabilities but may require fine-tuning for specific use cases to optimize performance.
If real-time querying and handling highly dynamic workloads are critical, Snowflake may be a better fit for you. Whereas, for fast querying performance on complex datasets, Redshift is more suitable.
Alignment with organizational security and compliance standards: Data security and compliance are paramount when selecting a data warehousing platform. Both Snowflake and Redshift offer robust security features, but they differ in implementation. Snowflake provides built-in security features, including encryption and role-based access controls, while Redshift offers customizable security options.
You can evaluate the specific security requirements of your organization to see how well each platform aligns with those standards. If your organization wants to control its data security, then Redshift fits your security use case better. On the other hand, if your organization requires fully-managed security features, Snowflake is more suitable.
Actionable takeaways for decision makers
Here are actionable takeaways for decision-makers considering Snowflake and Amazon Redshift for their data warehousing needs:
Evaluating Snowflake
- Evaluate concurrency needs: Determine if your organization requires a data warehousing solution that can handle high levels of concurrency with both queries and users. Snowflake's architecture separates compute and storage, making it suitable for virtually unlimited concurrency.
- Consider data size and latency: If you primarily work with smaller data sets and require minimal latency, Snowflake may be a strong fit for your needs. Assess whether your data workloads align with Snowflake's capabilities in this regard.
- Explore multi-cloud benefits: If multi-cloud flexibility is essential to your organization to prevent vendor lock-in and leverage strengths from various cloud providers, Snowflake's support for Azure, AWS, and GCP makes it a versatile choice.
- Ask about migration and integration: Inquire about Snowflake's migration tools and integration options to ensure a smooth transition and compatibility with your existing data infrastructure.
Evaluating Redshift
- Assess data scale: If your organization deals with petabyte-scale data sets and requires fast processing at a cost-effective price-performance ratio, Amazon Redshift may be a strong contender.
- Leverage AWS ecosystem: Consider using Redshift if your organization is heavily invested in AWS products and plans to leverage the broader AWS ecosystem for advanced data analytics, machine learning, and other cloud services.
- Node type customization: Assess whether the ability to choose specific node types for your data warehouse clusters aligns with your cost optimization and performance requirements.
- Evaluate pricing flexibility: Explore Redshift's pricing options, including on-demand, reserved instances, and concurrency scaling charges, to determine the most cost-effective model for your organization.
General actions
- Internal needs assessment: Conduct an in-depth assessment within your organization to understand your specific data warehousing requirements, including data volume, concurrency, latency, and integration needs.
- Trial runs: Consider running trial deployments with both Snowflake and Amazon Redshift to assess their performance, scalability, and compatibility with your existing data ecosystem.
- Cost analysis: Calculate the total cost of ownership for each platform, factoring in immediate costs, personnel training, maintenance, potential downtimes, and migration costs.
- Seek industry insights: Look for industry peers or organizations with similar use cases to gather insights and best practices from their experiences with Snowflake and Amazon Redshift.
- Engage with vendor support: Reach out to Snowflake and AWS to discuss your specific requirements and obtain guidance on implementation and migration.
Introducing PopSQL: Modern SQL editor for Snowflake and Redshift
Regardless of whether you opt for Snowflake or Redshift, having the right tools to complement your chosen data warehousing platform is crucial. Enter PopSQL, the modern SQL editor that streamlines database management and elevates data analysis capabilities. It seamlessly integrates with various database types, offers flexible connectivity options, and supports both on-premises and cloud connections.
With user-friendly features like interactive charts, dashboards, and real-time collaboration, PopSQL empowers data professionals across multiple databases. It provides query scheduling, version control, and robust security features to streamline data management and protect your data.
By integrating PopSQL, you can unlock the full potential of Snowflake and Redshift, making data exploration and analytics effortless and rewarding. Learn more about PopSQL by requesting a demo with us.
FAQs
How do Snowflake and Redshift differ in terms of architecture?
Snowflake follows a multi-cluster, shared data architecture, while Redshift uses a massively parallel processing architecture.
How do Snowflake and Redshift handle data collaboration?
Snowflake offers native data-sharing capabilities, enabling secure collaboration with external partners, while Redshift relies on manual data movement.
Which platform should I choose-Snowflake or Redshift?
The choice depends on specific use cases and requirements; consider factors like data types, scalability, and integration needs.
How do PopSQL and Snowflake/Redshift complement each other?
PopSQL is a modern SQL editor that seamlessly interacts with Snowflake and Redshift both, simplifying database management and analysis.
Can PopSQL be used with databases other than Snowflake and Redshift?
Yes, PopSQL supports a wide range of databases, making it versatile for various data management tasks.
Which is cheaper-Snowflake or Redshift?
The cost comparison between Snowflake and Amazon Redshift can vary widely depending on factors such as usage, data volume, and specific configurations. Both platforms offer pricing models based on usage, and the choice between them should be driven by your organization's unique requirements and cost optimization efforts. It's essential to be aware that Snowflake can incur hidden costs as usage scales, potentially leading to higher expenses. In contrast, Amazon Redshift is often considered cost-efficient, offering more predictable pricing structures. To make an informed decision, conduct a thorough cost analysis tailored to your organization's unique needs and consider both platforms' cost implications carefully.
