Detecting Spikes in Issues from Support Tickets
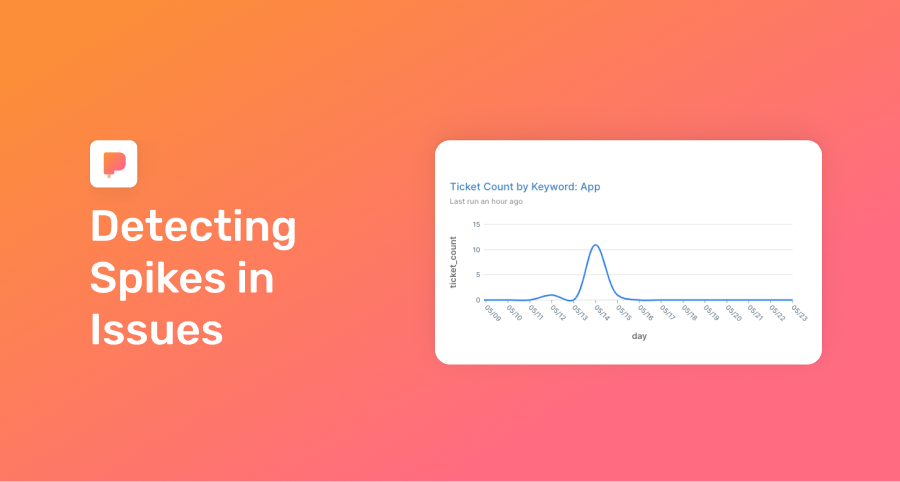
Here’s a surprisingly simple yet powerful way to monitor key systems.
We’ve battle-tested this approach at previous companies. It often alerted us of issues hours ahead of other feedback loops. It relies on customers reporting issues via support tickets. While it’s not ideal that users encounter the issue, it’s better than letting an issue fester. We call this approach “the seismograph”:

Why SQL?
We’ve yet to find an analytics solution baked into a support tool that’s easy to use and not siloed off from the rest of the business.
Therefore, it’s necessary to get data out of a support tool and into a database. Enter SQL.
Approach
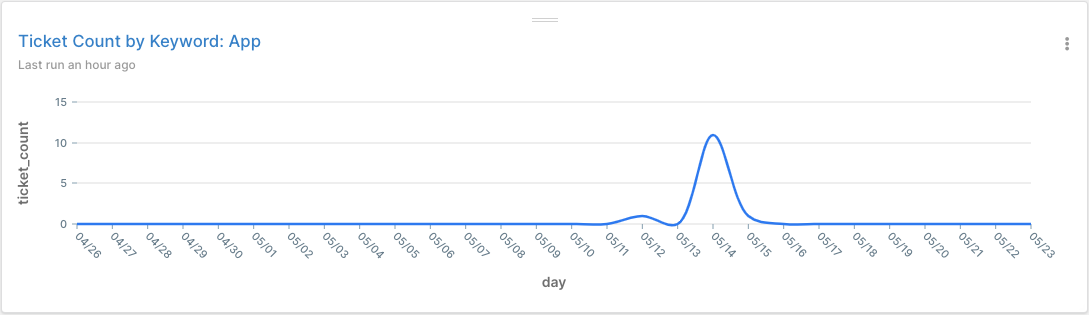
The query below searches support tickets for a keyword (e.g. sign-up, checkout, crash, app, Android, etc). You can monitor if people write in about a particular keyword at an anomalous rate:
SQL you can copy / paste
We use the generate_series() function so that our time series doesn’t have any gaps (see our tutorial, which shows how to create a rolling interval). The benefit: any days without tickets matching our keywords are reported as 0 instead of omitted altogether.
Here’s the output of the CTE in first part of the query:
| day |
|---------------------|
| 2020-04-26 00:00:00 |
| 2020-04-27 00:00:00 |
| 2020-04-28 00:00:00 |
| 2020-04-29 00:00:00 |
| ... |The latter part of the query joins our tickets table against our gapless series. It then gives a count of tickets matching our specified keywords:
with days as (
select generate_series(
'2020-04-26 00:00:00', -- start of interval
'2020-05-23 00:00:00', -- end of interval
'1 day'::interval -- increment
) as day
)
select
days.day,
count(1) filter (where tickets.initial_message ~* '(Auto)|(organize)') as ticket_ct -- the keywords you’re searching for, case insensitive
from days
left join tickets on date_trunc('day', tickets.created_at) = days.day
group by 1;Output:
We use a bit of Regular Expressions (Regex) in the query above (we also use Regex in our tutorial on Filtering Users by Version History). If you’re not familiar with Regex you can swap out the line with the keywords to:
count(1) filter (where LOWER(tickets.initial_message) similar to '%(auto|organize)%') as ticket_ctUse LOWER() on the initial_message column because similar to is case sensitive. You don’t want to exclude a ticket based on capitalization.
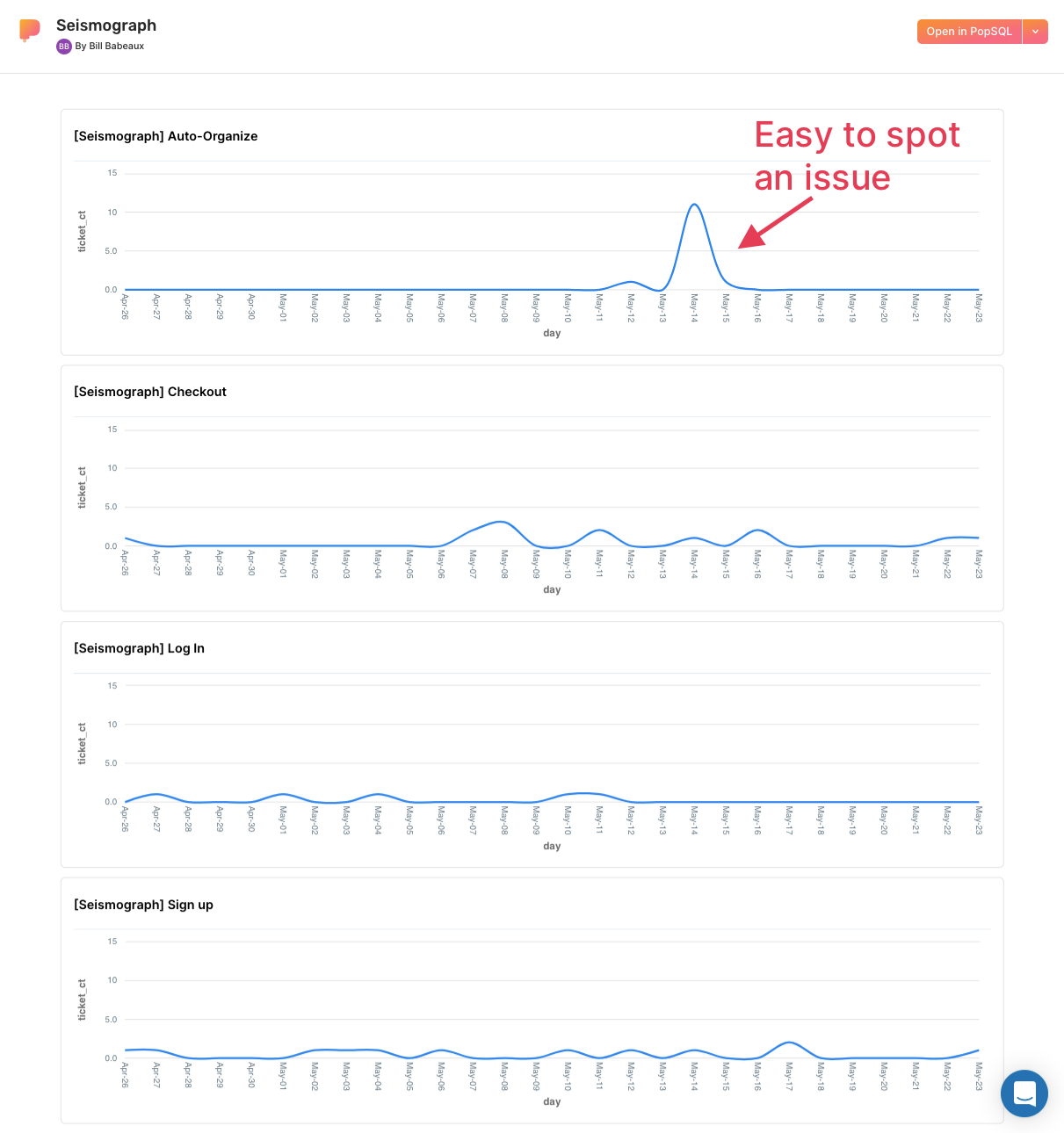
Final step: monitor multiple keywords
You can fork/clone the query above and swap out keywords. Then you can assemble your queries into a dashboard and view multiple at once:
Try it yourself?
Run this template against our sample database that mirrors real startup data. See the connection credentials, then connect in PopSQL.
Pro Tips
Getting tickets into your DB
- Getting your tickets into your DB is fairly straightforward. For example, Fivetran has solutions for ZenDesk and Intercom, as does Stitch Data (ZenDesk and Intercom).
- Note: if you have a slow ETL process (i.e. once daily), your feedback loop is going to be delayed.
- If you happen to have other sources of feedback in your production data (say, in-app feedback), consider using that instead of tickets.
Why search text? Why not rely on tags, buckets, etc?
Analyzing the raw text is faster for this purpose. Manually categorizing tickets by support agents often delays the feedback loop by hours, if not days.
Push this data to where you’ll see it
With PopSQL, you can schedule this dashboard to refresh (hourly, daily, etc) and push to your team’s Slack support channel.
